分布式基础 - 唯一ID生成算法
一、意义
分布式场景下,常常会有生成全局的唯一 ID 的需求,例如支付系统中会有支付 ID、退款 ID 等,实现的方式也是各有不同,生成的 ID 一般期望具备以下全部或部分特性:
- 唯一:要保证生成的 ID 是全网唯一的
- 有序递增:生成的 ID 对于某个用户或业务是按一定数字有序、递增的
- 高可用性:确保任何时候都能生成正确的生成 ID
- 带时间:ID 里面要包含时间信息
二、策略
2.1 UUID
2.1.1 原理
结合机器的网卡、当地时间、一个随机数生成 UUID
- 优点:不依赖网络、生成简单、性能好,高可用
- 缺点:长度过常,存储冗余,无序且不可读,查询效率低
2.1.2 实现
在 Java中可以这么调用
String uuid = UUID.randomUUID().toString();
例如,此刻我生成的是:
4d0b5372-07be-45d9-8761-c01eeee43ecf
如果不想要 - 可以这样:
String uuid = UUID.randomUUID().toString().replace("-", "");
于是生成了:
eb7e00b4c9f944e09e250fb7910b227f
2.2 数据库自增 ID
2.2.1 原理
使用数据库的 id 自增策略,例如 MySQL 的 AUTO_INCREMENT ,并且可以使用两台数据库分别设置不同步长(每次增长的长度)
- 优点:数据库生成的ID绝对有序,生成简单,高可用
- 缺点:需要独立部署数据库实例,成本高,有性能瓶颈
可以部署数据库集群,设置不同步长,生成不重复的 ID 策略来实现高可用
2.2.2 实现
CREATE TABLE `mytable` (
`id` INT NOT NULL DEFAULT 0 AUTO_INCREMENT,
PRIMARY KEY (`id`)
) ENGINE = INNODB DEFAULT CHARSET = utf8;
2.3 Redis 自增 ID
2.3.1 原理
Redis 的所有命令操作都是单线程的,本身提供像 incr 和 increby 这样的自增原子命令,所以能保证生成的 ID 肯定是唯一有序的
- 优点:性能比数据库好,数字 ID 天然有序
- 缺点:需要引入 Redis 组件,需要编码和配置的工作量比较大
可以部署 Redis 集群,来获取更高的吞吐量,初始化集群每台 Redis 的初始值为不同的值,然后设置相同的步长,就可以获取不同的值
步长 = 5 的时候,可以部署 5 台 redis,产生唯一的 ID
A:1, 6, 11, 16, 21
B:2, 7, 12, 17, 22
C:3, 8, 13, 18, 23
D:4, 9, 14, 19, 24
E:5, 10, 15, 20, 25
步长 = 3 的时候,可以部署 3 台 redis,产生唯一的 ID
A:1, 4, 7, 10, 13
B:2, 5, 8, 11, 14
C:3, 6, 9, 12, 25
2.3.2 实现
Redis 的 INCR 命令
它是一个原子操作,效果是是将 redis 数据库中 key 的值加一并且返回这个结果。如果 key 不存在,将在执行加一操作前,将这个 key 的值设置为0,也就是说执行这个命令的结果是从 1 开始一直累加下去的
大概的最基本的思路如下:
public interface UUIDService {
Long fetchUUID(String key);
}
public class UUIDServiceImpl implements UUIDService {
@Override
public Long fetchUUID(String key) {
Jedis jedis = null;
try {
jedis = redisConnection.getJedis();
return jedis.incr(key);
} finally {
jedis.close();
}
}
}
2.4 雪花算法
2.4.1 原理
雪花算法生成的是64 位长度的一串带时间信息的唯一的 ID 序列
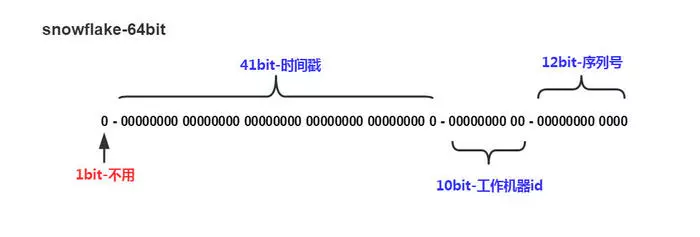
- 1 bit - 符号位:Java 中 long 型二进制是带符号的,最高位为符号位,正数为 0,负数为 1,实际系统中使用的 ID 一般是整数,所以最高位为 0
- 41 bit - 时间戳位(ms 级别):存储的是
当前时间 - 起始时间的时间戳,这里的起始时间戳一般是 ID 生成器开始是使用的时间戳 - 10 bit - 数据机器位:包括 5 位数据标识位,5 位机器标识位
- 12 bit - 毫秒内序列号位:同一台机器,同一时刻的节点,在每毫秒内生成的不重复的 ID 序列标识
时间戳的时间有效范围计算:
总共有 41 位,起始时间戳由程序自己指定,所以该时间戳可以表示的范围最多可以使用 69 年,因为总共 41 位,每一位可以有两种情况(0 或 1),那么总共可以表示 $2{41}$ 那么多种组合,也就是 $2{41}$ 那么多个数,$2^{41}$ = (1 << 41),那么个数除以一年的毫秒数量,就有 :(1 << 41)/ (1000 x 60 x 60 x 24 x 365) = 69 年
数据机器位的节点有效范围计算:
总共有 10 位,就代表不同机器 ID 一共有 $2{10}$ 种, 那么,一共可以部署 $2{10}$ 个机器不重复的机器节点,也就是 (1 << 10) ,超过这个数量,ID 可能就会生成冲突
毫秒内序列号的有效范围计算:
总共有 12 位,已知前面的时间戳部分可以标识当前的时间(毫秒级),前面的数据机器节点可以标识当前的机器节点,而这一部分就是用来标识在当前的时间,也就是当前毫秒内,在当前的机器节点中,生成的不同的 ID,总共 12 位,那么就有 $2^{12}$ 种组合,也就是说可以标识 4096 种 ID,也就说,一台机器在一个时间单位,也就是一毫秒内,最多可以生成 4096 个 ID
所以,雪花算法的组成大概就是时间戳位 + 数据机器位 + 毫秒内序列号位这样的思想生成唯一 ID 的
2.4.2 实现
以下实现摘自 Hutool 开源工具库的 Snowflake 实现:
public class Snowflake implements Serializable{
private static final long serialVersionUID = 1L;
// Thu, 04 Nov 2010 01:42:54 GMT
private final long twepoch = 1288834974657L;
private final long workerIdBits = 5L;
private final long datacenterIdBits = 5L;
//// 最大支持机器节点数0~31,一共32个
private final long maxWorkerId = -1L ^ (-1L << workerIdBits);
// 最大支持数据中心节点数0~31,一共32个
private final long maxDatacenterId = -1L ^ (-1L << datacenterIdBits);
// 序列号12位
private final long sequenceBits = 12L;
// 机器节点左移12位
private final long workerIdShift = sequenceBits;
// 数据中心节点左移17位
private final long datacenterIdShift = sequenceBits + workerIdBits;
// 时间毫秒数左移22位
private final long timestampLeftShift = sequenceBits + workerIdBits + datacenterIdBits;
private final long sequenceMask = -1L ^ (-1L << sequenceBits);// 4095
private long workerId;
private long datacenterId;
private long sequence = 0L;
private long lastTimestamp = -1L;
private boolean useSystemClock;
/**
* 构造
*
* @param workerId 终端ID
* @param datacenterId 数据中心ID
*/
public Snowflake(long workerId, long datacenterId) {
this(workerId, datacenterId, false);
}
/**
* 构造
*
* @param workerId 终端ID
* @param datacenterId 数据中心ID
* @param isUseSystemClock 是否使用{@link SystemClock} 获取当前时间戳
*/
public Snowflake(long workerId, long datacenterId, boolean isUseSystemClock) {
if (workerId > maxWorkerId || workerId < 0) {
throw new IllegalArgumentException(
StrUtil.format("worker Id can't be greater than {} or less than 0",
maxWorkerId));
}
if (datacenterId > maxDatacenterId || datacenterId < 0) {
throw new IllegalArgumentException(
StrUtil.format("datacenter Id can't be greater than {} or less than 0",
maxDatacenterId));
}
this.workerId = workerId;
this.datacenterId = datacenterId;
this.useSystemClock = isUseSystemClock;
}
/**
* 根据Snowflake的ID,获取机器id
*
* @param id snowflake算法生成的id
* @return 所属机器的id
*/
public long getWorkerId(long id) {
return id >> workerIdShift & ~(-1L << workerIdBits);
}
/**
* 根据Snowflake的ID,获取数据中心id
*
* @param id snowflake算法生成的id
* @return 所属数据中心
*/
public long getDataCenterId(long id) {
return id >> datacenterIdShift & ~(-1L << datacenterIdBits);
}
/**
*根据Snowflake的ID,获取生成时间
*
* @param id snowflake算法生成的id
* @return 生成的时间
*/
public long getGenerateDateTime(long id) {
return (id >> timestampLeftShift & ~(-1L << 41L)) + twepoch;
}
/**
* 下一个ID
*
* @return ID
*/
public synchronized long nextId() {
long timestamp = genTime();
if (timestamp < lastTimestamp) {
// 如果服务器时间有问题(时钟后退) 报错。
throw new IllegalStateException(
StrUtil.format("Clock moved backwards. Refusing to generate id for {}ms",
lastTimestamp - timestamp));
}
if (lastTimestamp == timestamp) {
sequence = (sequence + 1) & sequenceMask;
if (sequence == 0) {
timestamp = tilNextMillis(lastTimestamp);
}
} else {
sequence = 0L;
}
lastTimestamp = timestamp;
return (
(timestamp - twepoch) << timestampLeftShift) |
(datacenterId << datacenterIdShift) |
(workerId << workerIdShift) |
sequence;
}
/**
* 下一个ID(字符串形式)
*
* @return ID 字符串形式
*/
public String nextIdStr() {
return Long.toString(nextId());
}
/**
* 循环等待下一个时间
*
* @param lastTimestamp 上次记录的时间
* @return 下一个时间
*/
private long tilNextMillis(long lastTimestamp) {
long timestamp = genTime();
while (timestamp <= lastTimestamp) {
timestamp = genTime();
}
return timestamp;
}
/**
* 生成时间戳
*
* @return 时间戳
*/
private long genTime() {
return this.useSystemClock ? SystemClock.now() : System.currentTimeMillis();
}
}
Comments