消息队列 - RabbitMQ 理论基础篇
本文主要介绍 RabbitMQ 的各种入门基础,讲解的都是 HelloWorld 等级的东西:
- 基础概念
- 原语使用
- 应用场景
一、基础概念
1.1 RabbitMQ
就是一个队列,跟 Java 的容器 LinkedList 一样也是队列,只不过不同的是,这个队列很强大,它是分布式系统中,作为服务节点之间通讯使用的队列,最起初源于金融系统,用于分布式系统中存储转发消息,所以它名字就叫做 “消息” 队列
1.2 消息队列协议
我们的 Web 应用常用的协议是 HTTP,而队列中消息通讯也有协议,这就是所谓的消息队列协议,RabbitMQ 中用的协议叫做,AMQP(Advanced Message Queuing Protocol,高级消息队列协议),当然消息队列协议跟 Web 通讯协议一样,也是有很多种的,例如 STOMP、MQTT 等,这俩协议,RabbitMQ 也支持
1.3 RabbitMQ 整体架构
架构图如下:
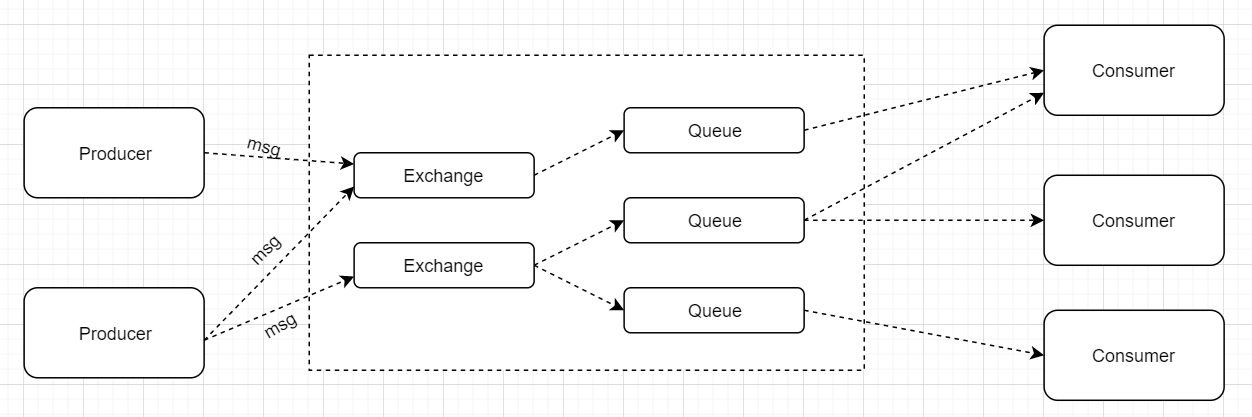
可以看到组成的角色有:
- Producer
- Message
- Exchange
- Queue
- Consumer
以下篇章会详细介绍这些角色
二、组成
首先明确以下,消息队列中的常见的等价角色
- 发布者 Publisher = 生产者 Producer
- 订阅者 Subscribers = 消费者 Consumer
2.1 Producer
Producer 生产者,它是生产(发布)消息的一方
2.2 Message
消息,消息一般由两部分组成
- Label,消息头
- Payload,消息体
2.2.1 Label
消息头是一些列可选的属性组成,包括:
- Routing Key,路由键
- Priority,相对于其他消息的优先级
- Delivery mode,设置消息的持久性
消息头的作用如下
- 生产者把消息交给交换器
- 交换器根据消息头的 Routing Key 和消息队列的 Binding Key,路由消息给消息队列
- 消息队列根据消息头里面的信息把消息给感兴趣的消费者
2.2.2 Payload
消息体是不透明的,是消息的数据体,可以是任何数组,比如 JSON、自定义数据等
2.3 Exchange
2.3.1 作用
Exchange 交换器,它的职责如下:
生产者者将消息给交换器后,消息不会马上投放到消息队列 (Queue),而是把消息给交换器
- 如果路由成功,交换器将消息路由给服务器中的队列
- 如果路由不到,就会返回给生产者,或者直接丢弃
2.3.2 路由流程
- 生产者生产消息,消息的消息头会指定一个 Routing Key
- 生产者把消息扔给交换器
- 交换器与消息队列通过 Binding Key 绑定
- 交换器根据消息的 Routing Key 与消息队列的 Binding Key 根据路由策略匹配,从而把消息路由给消息队列
可以看到,交换器就好像一个由绑定构成的路由表,同时,交换器与消息队列的绑定可以是多对多的关系
2.3.3 类型
每个交换器,都会设定一种路由策略,交换器总共有四种路由策略,也就代表着四种交换器类型:
- Direct
- Fanout
- Topic
- Header
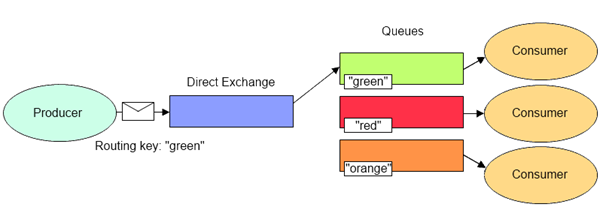
2.3.4 Exchange - Direct
直接模式,也就是指定队列模式,把消息路由到那些 BindingKey 与 RoutingKey 完全匹配的 Queue 中,其他的 Queue 都收不到
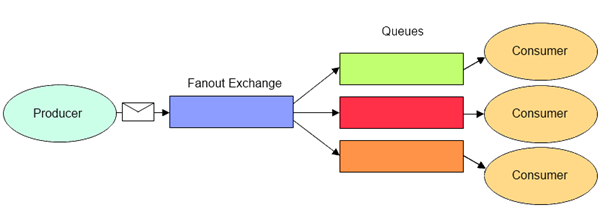
2.3.5 Exchange - Fanout
扇出模式,也就是广播模式,把消息路由到与它绑定的所有 Queue 中(没有 key 的匹配了,绑定就可以用)
2.3.6 Exchange - Topic
主题模式,会先设定一个主题,然后把消息路由给指定主题能够匹配上的主题中,是特别常用的模式
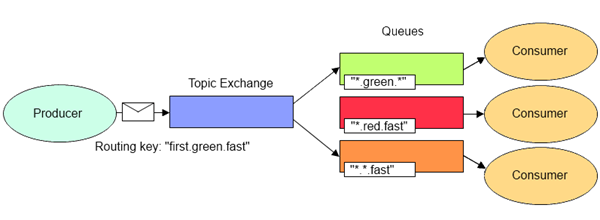
把消息路由到 BindingKey 和 RoutingKey 完全匹配的 Queue 中,跟 Direct 差不多,但不一样的是匹配规则有扩展,这个匹配规则,其实就是所谓的 主题,主题的格式如下:
- RoutingKey 和 BindingKey 格式一样,是一个被 "." 分隔的字符串,例如 "com.jalr.queue.client" 或者 "com.jalr.cloud.client"
- BindingKey 中可以存在两种特殊字符串 "*" 和 "#" 来做模糊匹配
- "*" 匹配一个单词
- "#" 匹配多个单词(0 个也可以)
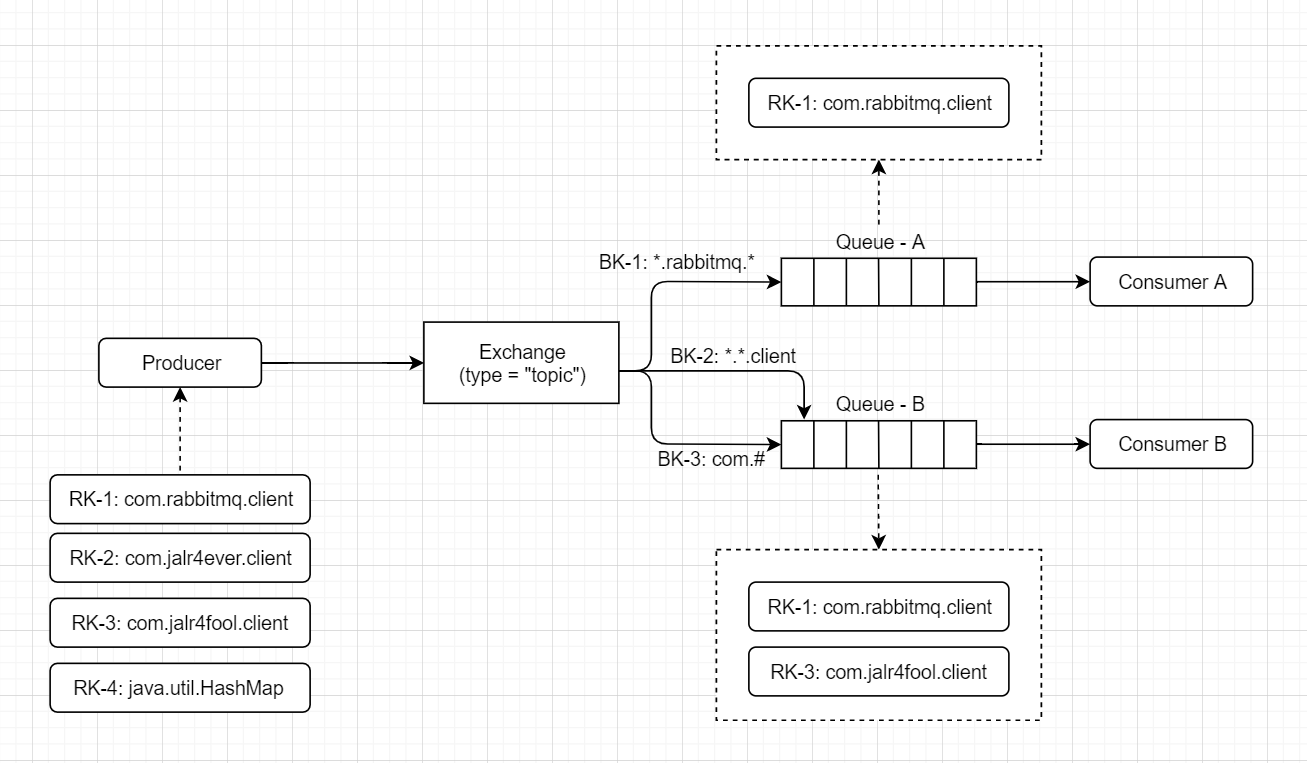
例如,上面生产了四个消息,RK 对应表示消息的 Routing Key,而 BK 对应表示交换器绑定的消息队列的 Binding Key(其实 Binding Key 也是 Routing Key,只是换个叫法区分消息和消息队列而已)
那么路由结果为:
- RK - 1 路由到了 Queue - A 和 Queue - B (用的是 BK-1 和 BK-2 的规则)
- RK - 2 路由到了 Queue - B (用的是 BK-2 的规则)
- RK - 3 路由到了 Queue - B (用的是 BK-2 的规则)
- RK - 4 路由失败,会被丢弃或者返回给生产者
2.3.7 Exchange - Headers
头部模式,这种类型的策略,不依赖于路由键的匹配规则来路由消息,而是根据发送的消息内容中的 headers 属性进行匹配
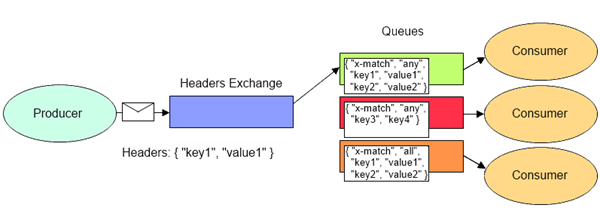
路由过程如下
- 绑定消息队列和交换器时,制定一组键值对
- 生产者发送消息到交换器,RabbitMQ 获取消息的 Header(键值对格式),比较键值对是否完全匹配队列和交换器绑定时制定的键值对
- 完全匹配键值对,路由消息到该队列
- 否则不路由到队列
Header 交换器性能差,不实用,基本不用这个
2.4 Queue
Queue 消息队列,用来保存消息的容器,消息经由交换器,存放在消息队列,等待消费者取走消息
- 消息队列跟消息的
路由关系可以是:一对多,多对一,多对多的关系 - 消息队列跟消费者的
订阅关系也可以是:一对多,多对一,多对多的关系
注意:这里是订阅,不是消费!重复消费的现象是绝对不允许的!
重复消费:一个消费者重复消费了同一个队列的同一个消息多次
思考 - 1:多消费者订阅同一队列的重复消费?
当多消费者订阅同一个队列,那么消息会轮询给多个消费者消费,而不是每个消费者都收到所以消息处理,这样可以避免消息被重复消费
思考 - 2:一个消息投放给多个队列的重复消费?
一个消息,在 fanout 策略下,可能会被路由到多个队列,想着可能会发生多个消费者拿到了同一消息发生了重复消费,而实际上,如果 mq 会控制这种消费组里的消费,当 MQ 收到了客户端的确认消费之后,就结束了,如果收不到,才继续推送消息到消息队列
思考 - 3,一个消费者消费了多个不同队列里的同一消息是重复消费么?
思考一下,由于 fanout 模式下,是可以将同一个消息路由到多个队列的,思考两个问题:
- 由于订阅关系是消费者可以定于有没有可能出现一个消息投放到多个队列,而同一个消费者订阅这多个队列,然后消费了多个队列的同个消息?
- 这种消费的情况是不是重复消费?
对于第一个问题,是不可能发生的,首先可能会有一种错误的理解,消费者可以订阅多个队列同时获取多个消息,但其实消息队列的模式是单线程的,同一时间,消费者线程只能监听一个队列,除非是多线程,所以同一时间也只能消费一个消息,消费其他队列的消息,是代码上来指定的,只有当自己当前监听的队列消息都完了才能监听其他队列消费消息,而往往这是不可能发生的
对于第二个问题,和网上普遍的情况定义不一样,但本质来看,其实也是重复消费,但基本是不可能发生这种消费情况的,不需要想太多
思考 - 4,重复消费的解决方案?
消息队列使用的时候要进行幂等性设计
2.5 Broker
对于 RabbitMQ 来说,一个 RabbitMQ Broker 可以简单地看作一个 RabbitMQ 服务实例
业务方,可以将自己的业务数据生产出相应的消息,然后由 Broker ,也就是服务实例来进行路由发布,消费者就会从 Broker 得到消息,进行反序列化,拿到相应的数据
三、应用场景
RabbitMQ 还是可以用于消息队列常见三大场景:异步、削锋、解耦
3.1 用户注册
用户注册的时候,可能会发送一个注册邮件还有一个注册短信提示注册成功的信息,此时,这个业务可以不用等待发送的两个操作,而是作为两个消息投放给消息队列,异步执行,从而提高用户响应体验
3.2 支付解耦
订单系统,下完单了,会更新库存系统,如果没有消息队列,可能库存系统挂了,就会影响到订单系统,导致不可用
有了消息队列,可以把两个模块解耦,订单支付信息封装成一个消息投放到消息队列,库存系统去获取消息,更新库存,这时就算库存系统挂了,订单系统依旧可以执行
3.3 流量削锋
消息队列可以应用于大流量的请求,此时可以将请求放到消息队列中,然后以可控的量去消费消息队列的消息
3.4 订单支付
常常看到,订单 30 分钟内支付有效的倒计时支付,此时支付信息其实就是存放在一个消息队列中,在 RabbitMQ 中,使用的就是死信队列 / 延迟队列来做的
首先看看死信队列是一套特殊的组件,可以说:死信队列 = 队列 + 死信交换机 + 死信路由 + TTL(消息存活时间),也就说一个死信队列里面也是会有一个队列,但这个队列很特殊,可以配置一些 TTL 之类的参数,然后当里面的消息过期了,就会按照自己的配置的策略去做一些操作
如果用来做订单超时处理,一般的流程大概如下:
- 用户下单成功,将待支付状态的订单数据实体放入死信队列
- 死信队列设置有消息的过期时间,死信队列会有一套机制去检测消息的是否过期(轮询之类的算法)
- 消息过期,说明用户没有支付,则放入用户支付超时处理的队列,让消费者进行支付失败的消息消费
- 消息未过期,也就是用户前端点 “支付” 了!则死信队列把支付消息给支付成功的队列,让消费者进行支付成功的消息消费
参考上面的流程,也可以发现,死信队列其实是有很大的问题的,因为消息要被消费了,死信队列才会转发下一个消息,如果有一个消息迟迟没有消费,后面的一堆消息就干等着了!其实本来那个消息可以消费的,但硬是等前面的,就等超时了!这就是所谓的阻塞现象!
所以,一般来说,用死信队列,不会只设置一个队列,而是通过多个死信队列来做的超时处理,减少消息阻塞
Comments