工程经验 - 大模型 Agent 入门指南
ChatGPT 3.5 的发布恍若 IPhone 4。我们可以选择去相信,犹如移动互联一样,LLM 将开启一个新的时代
本文是个大杂烩,但这些大杂烩对于成为一名大模型 Agent 开发者将是有助于 or 必要的
本文主要讨论:
- 什么是大模型 Agent?
- 如何开发一个大模型 Agent?
- 大模型 Agent 的玩家有哪些?
- 大模型 Agent 有哪些趋势?
@Date 2024/01/23 17:00
一、大模型 Agent
1.1 概念
LLM Agent 是一种能产出不单是简单文本的 AI 系统,使用 LLM 的能力,作为其计算引擎,让自己能够对话、任务执行、推理,实现一定程度的自主行动
可以说,在这个大模型 AI 时代下,大模型应用 or AI Power + 的应用就是大模型 Agent,等同于移动互联时代的 APP
1.2 构成
目前行业内对对于 LLM Agent 没有一个统一明确的定义,不过大家的概念定义都类似
1.2.1 MetaGPT 定义的 Agent
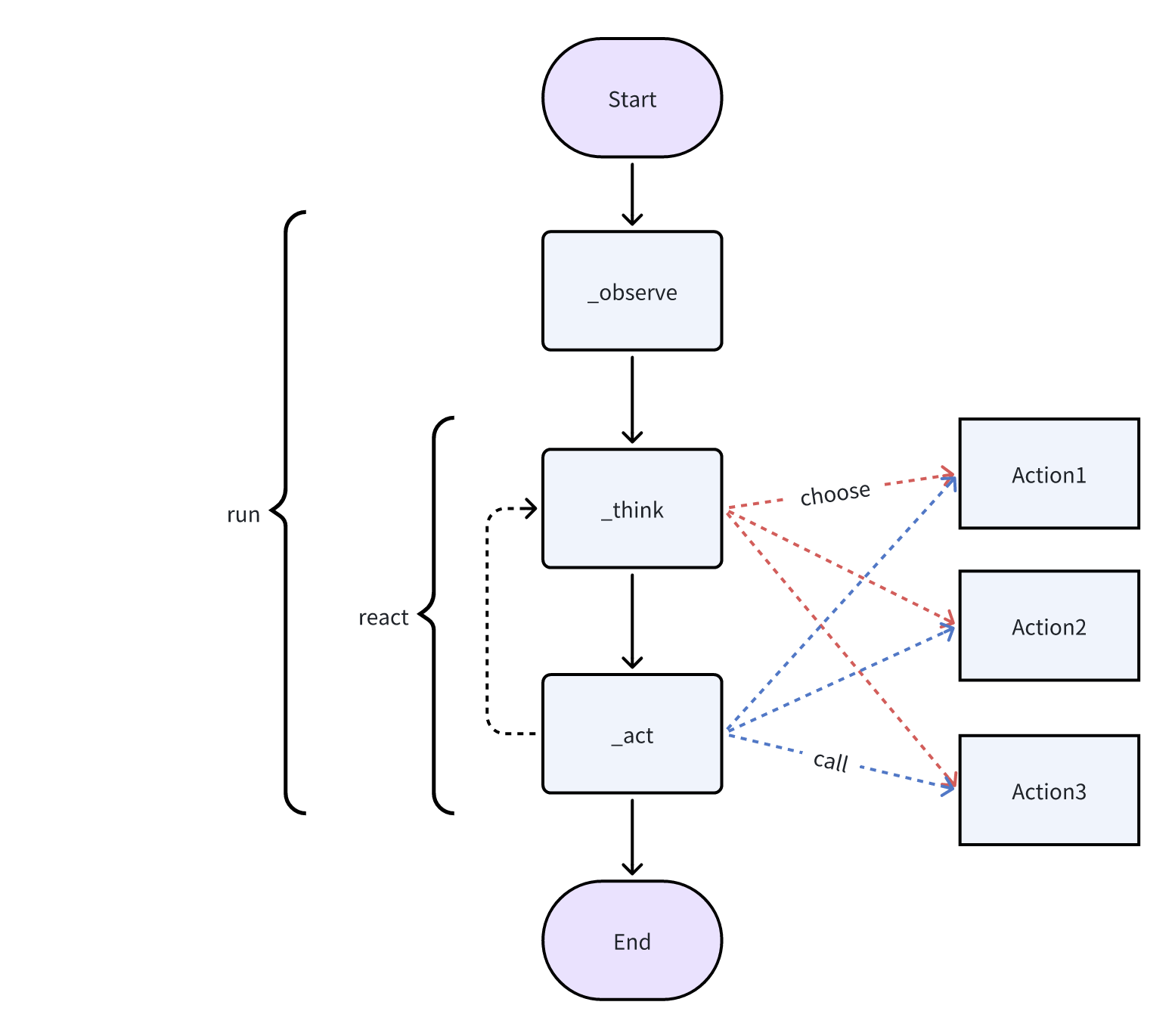
Agent = 大模型(LLM)+ 观察 + 思考 + 行动 + 记忆
- 大模型(LLM):LLM 是代理的“大脑”之一。
- 观察:这是代理的感知机制,使其能够感知其环境。
- 思考:思考过程涉及分析观察结果,借鉴记忆,并考虑可能的行动。
- 行动:这些是代理对其思考和观察的可见响应。
- 记忆:代理的记忆存储过去的经验。
1.2.2 Lilian 定义的 Agent
Lilian - OpenAI AI 安全团队 leader
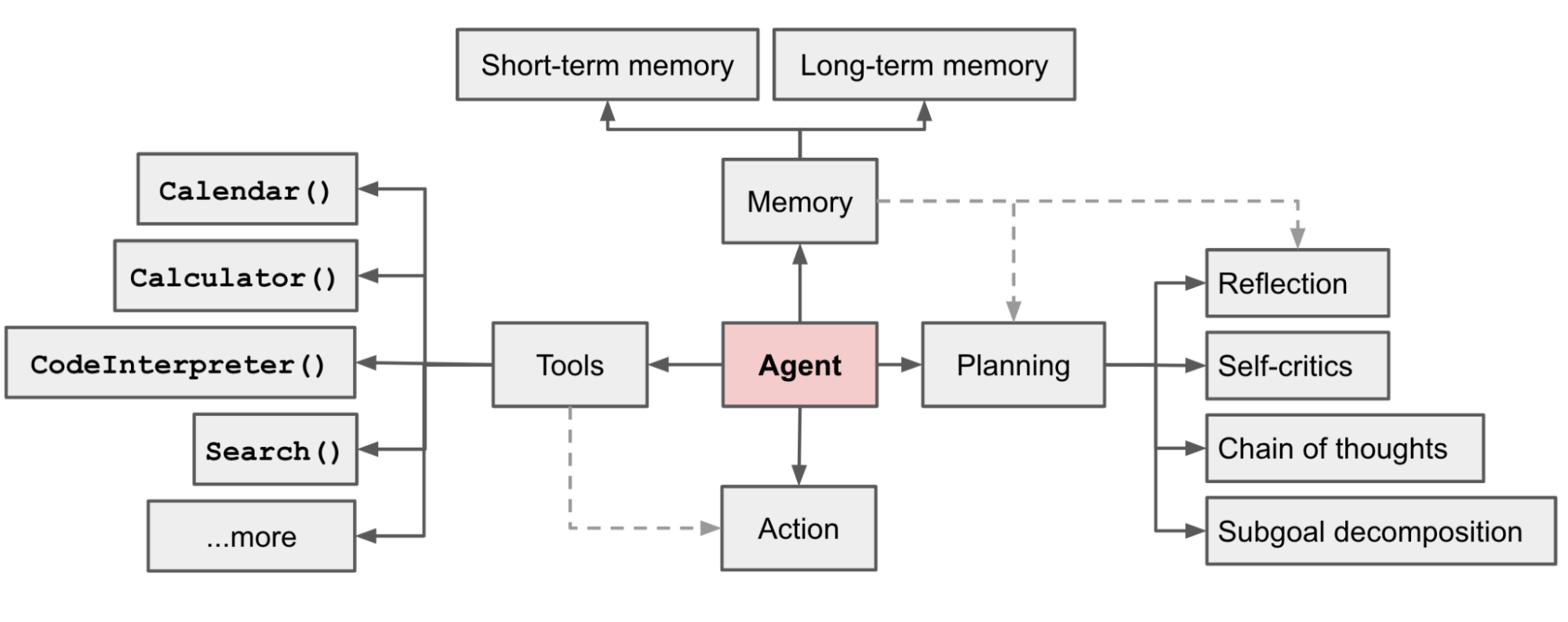
Agent = 大模型(LLM)+ 工具使用 + 规划 + 行动 + 记忆
在由LLM驱动的自主代理系统中,LLM作为代理的大脑,辅以几个关键组件:
- 规划
- 子目标和分解:代理将大型任务分解为较小、可管理的子目标,从而实现对复杂任务的高效处理。
- 反思和完善:代理可以对过去的行动进行自我批评和自我反思,从错误中学习并为未来的步骤做出改进,从而提高最终结果的质量。
- 记忆
- 短期记忆:我认为所有上下文学习(请参见提示工程)都利用了模型的短期记忆来学习。
- 长期记忆:这为代理提供了在较长时间内保留和检索(无限)信息的能力,通常通过利用外部向量存储和快速检索来实现。
- 工具使用
- 代理学习调用外部API以获取缺失于模型权重中的额外信息(通常在预训练后难以更改),包括当前信息、代码执行能力、访问专有信息源等。
1.3 开发
1.3.1 框架
从 LLM Agent 的构成来看,开发一个 Agent 其实就是开发它们的各个组件,这里使用 MetaGPT,MetaGPT 是一个 Agent 应用,同时也是一个开发框架。它可以作为一个软件开发公司角色,也可以作为框架使用其中的 Agent 抽象快速开发 Agent
1.3.2 安装 miniconda
注意:我的环境是 Ubuntu 22.04
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh
过程注意看提示,默认安装在 /root/ 下,非普通用户权限,如果是普通用户可以输入在 /home/ 目录下进行安装
环境变量
安装完成后,terminal 无法使用 conda 命令,除非输入以下切换到 root 用户 sudo su ;原因:是安装更改的是 root 用户的 ~ 目录的 .bashrc,也就是 /root/ 下的 .bashrc
因此需要 cat /root/.bashrc,将最后一段 miniconda 的环境变量配置 copy 到普通用户的 ~/.bashrc 底下,再进行即可
source ~/.bashrc
1.3.3 Hello Word
这里注意,项目会读取 ~/.metagpt/config.yaml 目录下的文件,要将这个配置文件的 OPENAI KEY 注释打开,填入
# Step 1: Ensure that Python 3.9+ is installed on your system. You can check this by using:
# You can use conda to initialize a new python env
# conda create -n metagpt python=3.9
# conda activate metagpt
python3 --version
# Step 2: Clone the repository to your local machine for latest version, and install it.
git clone https://github.com/geekan/MetaGPT.git
cd MetaGPT
pip3 install -e . # or pip3 install metagpt # for stable version
# Step 3: setup your OPENAI_API_KEY, or make sure it existed in the env
mkdir ~/.metagpt
cp config/config.yaml ~/.metagpt/config.yaml
vim ~/.metagpt/config.yaml
# Step 4: run metagpt cli
metagpt "Create a snake game in python"
初步体验:
- gpt-4:大约花费 4 块钱,写了一个贪吃蛇游戏,能启动,能玩,按键有错位
- gpt-35:大约花费 1 块钱,写了一个贪吃蛇游戏,无法启动;尝试两次均无法启动
hello word 能启动的话,说明环境配置已经完成,可以基于已有的环境写 Python 开发 Agent
1.3.4 实例-编码 Agent
说明:
- Action:其实就是封装 Prompt 和 LLM Call
- Role :Agent 的“实体“”。可以执行 Action 、拥有 Memory、具备 Think、选择 Strategies
定义 Action
import re
from metagpt.actions import Action
class SimpleWriteCode(Action):
PROMPT_TEMPLATE: str = """
Write a python function that can {instruction} and provide two runnnable test cases.
Return ```python your_code_here ``` with NO other texts,
your code:
"""
name: str = "SimpleWriteCode"
async def run(self, instruction: str):
prompt = self.PROMPT_TEMPLATE.format(instruction=instruction)
# 调用 llm,发送 prompt
rsp = await self._aask(prompt)
# 拿到 prompt
code_text = SimpleWriteCode.parse_code(rsp)
return code_text
@staticmethod
def parse_code(rsp):
pattern = r"```python(.*)```"
match = re.search(pattern, rsp, re.DOTALL)
code_text = match.group(1) if match else rsp
return code_text
定义 Role
from metagpt.logs import logger
from metagpt.roles import Role
from metagpt.schema import Message
from self_example.write_code_angent.SimpleWriteCode import SimpleWriteCode
class SimpleCoder(Role):
name: str = "Alice"
profile: str = "SimpleCoder"
def __init__(self, **kwargs):
super().__init__(**kwargs)
self._init_actions([SimpleWriteCode])
async def _act(self) -> Message:
# 拿到要做的 Action - SimpleWriteCode
logger.info(f"{self._setting}: to do {self.rc.todo}({self.rc.todo.name})")
todo = self.rc.todo # todo will be SimpleWriteCode()
# 从记忆中读取人类输入的最新指令,运行 Action,封装 Message,并响应
msg = self.get_memories(k=1)[0] # find the most recent messages
code_text = await todo.run(msg.content)
msg = Message(content=code_text, role=self.profile, cause_by=type(todo))
return msg
启动 Agent
import asyncio
from metagpt.logs import logger
from self_example.write_code_angent.SimpleCoder import SimpleCoder
async def main():
msg = "write a function that calculates the product of a list"
role = SimpleCoder()
logger.info(msg)
result = await role.run(msg)
logger.info(result)
# 调用 asyncio.run() 时传递 main() 函数,而不是直接调用它
asyncio.run(main())
输出结果:
2024-01-15 14:40:32.586 | INFO | __main__:main:9 - write a function that calculates the product of a list
2024-01-15 14:40:32.587 | INFO | self_example.write_code_angent.SimpleCoder:_act:17 - Alice(SimpleCoder): to do SimpleWriteCode(SimpleWriteCode)
```python
def calculate_product(lst):
product = 1
for num in lst:
product *= num
return product
# Test cases
print(calculate_product([1, 2, 3])) # Output: 6
print(calculate_product([4, 5, 6])) # Output: 120
```
2024-01-15 14:40:37.000 | INFO | metagpt.utils.cost_manager:update_cost:48 - Total running cost: $0.000 | Max budget: $10.000 | Current cost: $0.000, prompt_tokens: 70, completion_tokens: 74
2024-01-15 14:40:37.000 | INFO | __main__:main:11 - SimpleCoder:
def calculate_product(lst):
product = 1
for num in lst:
product *= num
return product
# Test cases
print(calculate_product([1, 2, 3])) # Output: 6
print(calculate_product([4, 5, 6])) # Output: 120
1.3.5 MultiAgent 开发
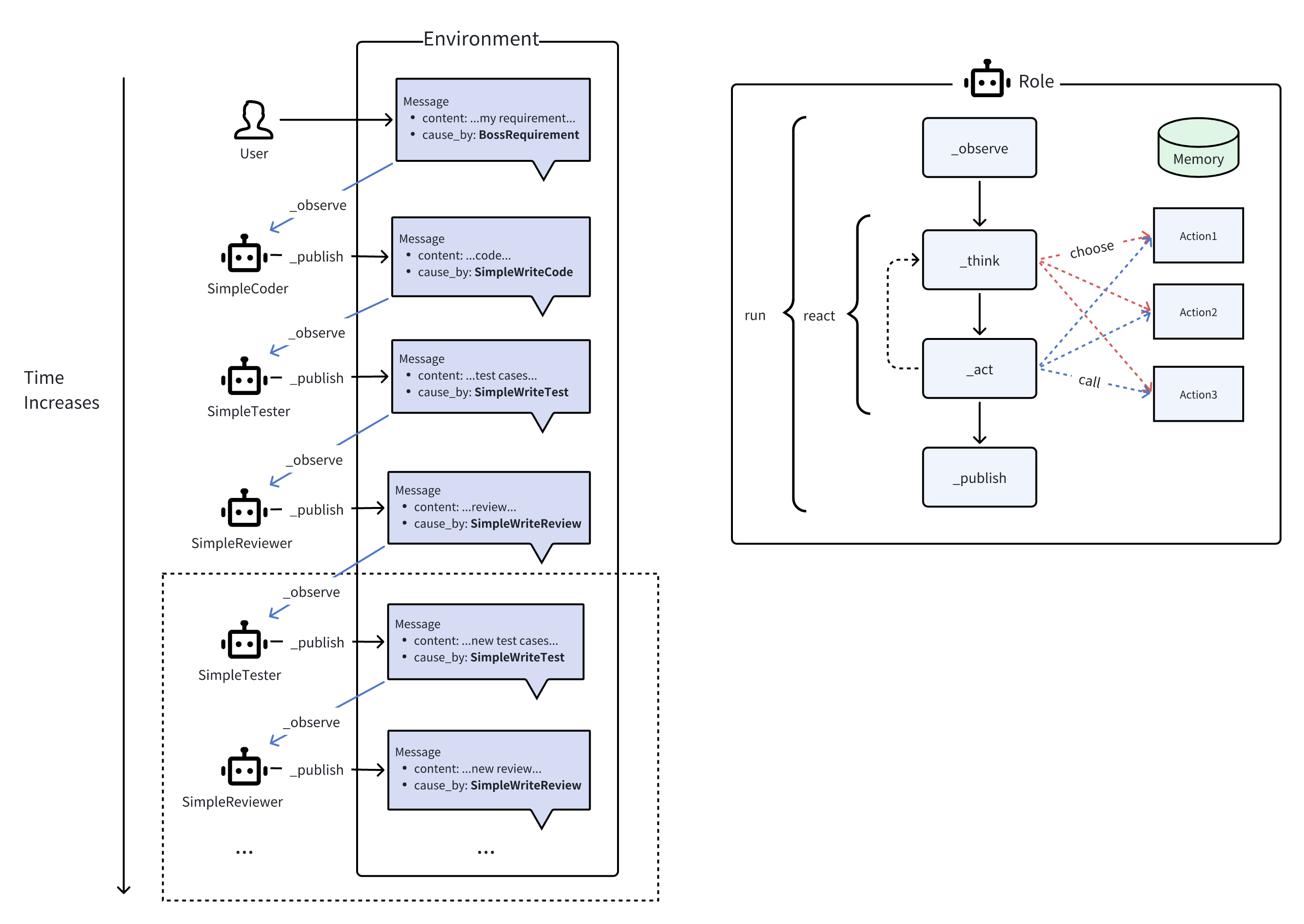
MetaGPT 还提供了 MultiAgent 开发,提出了招人、团队、环境、投资等概念,详细可见其官方 Doc
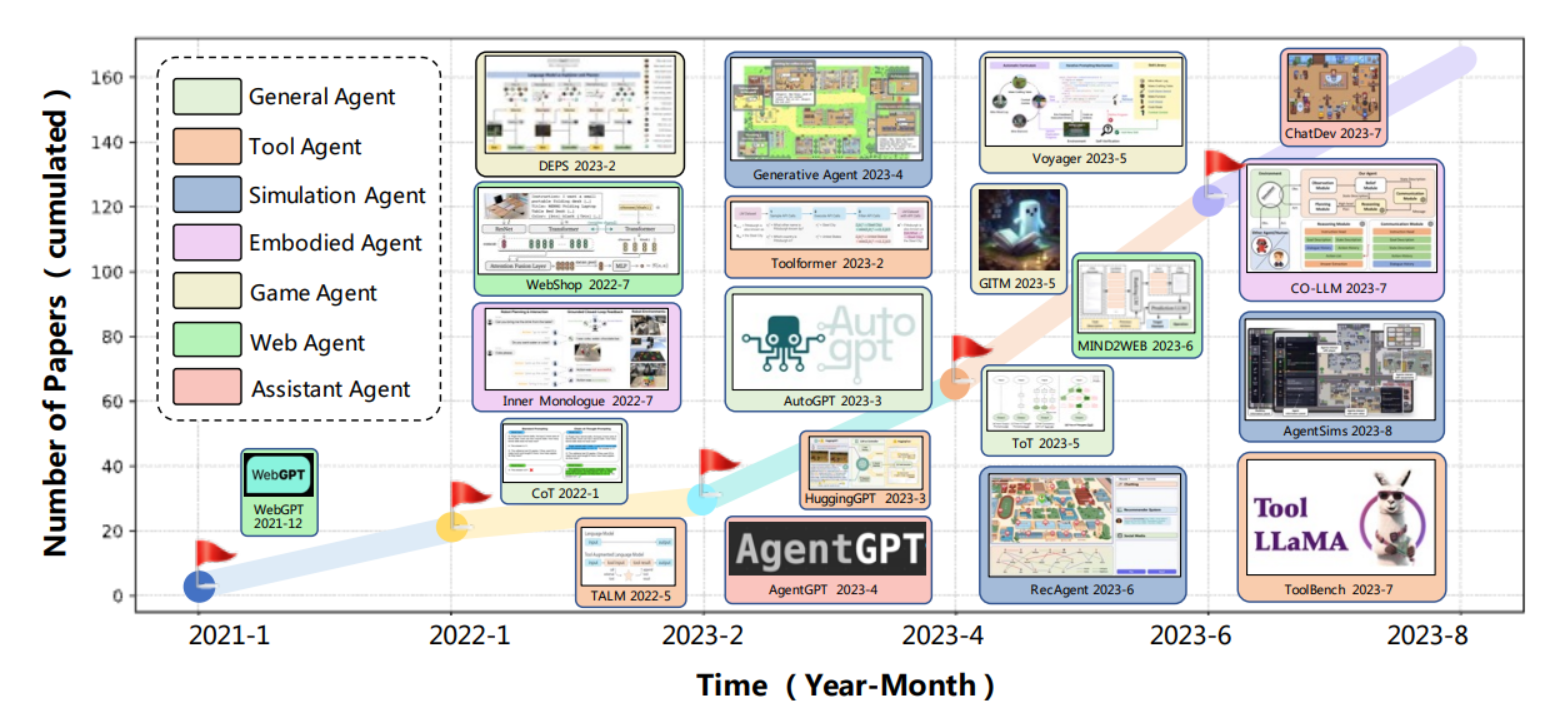
1.4 Agent 类型
A Survey on Large Language Model based Autonomous Agents
1.5 挑战 & 限制
其实综合体验下来,由于限制的 LLM 能力有限,不管是上下文或者是任务规划能力,最后 Agent 产出的内容没有一个是能直接投入生产的,毕竟写个贪吃蛇游戏都还是有问题的
1.5.1 UX issues
用户体验。LLM 可能出现反叛行为。
1.5.2 long-term planning and task decomposition
长期规划和任务分解。无法在面对不可预见的错误时改变计划。作为各应用的接口却存在无法保证的可靠性是个很大的问题。
1.5.3 Trust and privacy
安全问题。Agent 访问用户工具,如何确定它是安全的?独立执行 "管理员 "级别的任务(如发送电子邮件)如何保证安全?
1.5.4 Finite context length
语境上下文的交流长度是有限的。限制了历史信息、详细说明、应用程序接口调用上下文和响应的包含。虽然能进行矢量检索,但不够聚焦。
1.6 现阶段方向 & 思考
将人类的某些工作环节做自动化,任务越小,越明确,LLM 的幻觉越小,此时任务的实现效果越好,比如一些工具类的 Agent
但随着大模型能力的提升,现在许多的理念和效果不好的功能是非常有可能实现的
二、玩家
2.1 明星公司
了解头部明星公司产品,关注大家现在在卷什么方向
- OpenAI: ChatGPT
- Anthropic: Cluade.AI
- Character.ai
- Perplexity.ai
- Runway
- Pika
- VideoPoet
- Mistral AI
- Inflection ai : Pi
2.2 生态 & 研究
了解相关领域的发展,以及有哪些问题需要解决 https://github.com/DSXiangLi/DecryptPrompt
三、术语
- Logical reasoning: 逻辑推理
- RAG:检索增强生成;RAG 把一个信息检索组件和文本生成模型结合在一起。RAG 可以微调,其内部知识的修改方式很高效,不需要对整个模型进行重新训练
- Multimodal learning:多模态
- RLHF:从人类反馈中进行强化学习(Reinforcement learning from human feedback,RLHF)
- arxiv:大杂烩论文网站,没有什么级别。会将预稿上传到 arvix 作为预收录,因此这就是个可以证明论文原创性(上传时间戳)的文档收录网站 。
- AI Hallucinations:幻觉。大模型出现幻觉,简而言之就是“胡说八道”。
- pretraining data:预训练数据。了让模型学习到更广泛、更通用的语言知识和语义信息,,未进行标注或者部分标注
- training data:为了让模型学习到如何执行特定的任务,通常是经过标注的数据集
- reliability:模型可靠性,意味着更少的幻觉
四、提示工程
AI 领域相关的经典概念,参考:https://www.promptingguide.ai/zh
4.1 zero-shot Prompting
直接问
Q: <问题>?
A:
改进方案:通过指令描述的数据集上微调模型,RLHF(来自人类反馈的强化学习)用于扩展指令调整,其中模型被调整以更好地适应人类偏好。
4.2 Few-shot Prompting
举例-说明,再问
<问题>?
<答案>
<问题>?
<答案>
<问题>?
<答案>
<问题>?
改进方案:问题分解成步骤并向模型演示,这可能会有所帮助。思维链(CoT)提示
4.3 Chain-of-Thought Prompting - CoT
举例-说明中,强调解决问题的思路,再问
这组数中的奇数加起来是偶数:4、8、9、15、12、2、1。
A:将所有奇数相加(9、15、1)得到25。答案为False。
这组数中的奇数加起来是偶数:17、10、19、4、8、12、24。
A:将所有奇数相加(17、19)得到36。答案为True。
这组数中的奇数加起来是偶数:16、11、14、4、8、13、24。
A:将所有奇数相加(11、13)得到24。答案为True。
这组数中的奇数加起来是偶数:17、9、10、12、13、4、2。
A:将所有奇数相加(17、9、13)得到39。答案为False。
这组数中的奇数加起来是偶数:15、32、5、13、82、7、1。
A:
限制:足够大的语言模型才会出现的新兴能力
改进方案:少样本CoT采样多个不同的推理路径,并使用生成结果选择最一致的答案。SELF-CONSISTENCY-CoT
4.4 Self-Consistency Chain-of-Thought Prompting
多条举例-说明中,强调多种解决问题的思路,再问
Q:林中有15棵树。林业工人今天将在林中种树。完成后,将有21棵树。林业工人今天种了多少棵树?
A:我们从15棵树开始。后来我们有21棵树。差异必须是他们种树的数量。因此,他们必须种了21-15 = 6棵树。答案是6。
Q:停车场有3辆汽车,又来了2辆汽车,停车场有多少辆汽车?
A:停车场已经有3辆汽车。又来了2辆。现在有3 + 2 = 5辆汽车。答案是5。
Q:Leah有32块巧克力,她的姐姐有42块。如果他们吃了35块,他们总共还剩多少块?
A:Leah有32块巧克力,Leah的姐姐有42块。这意味着最初有32 + 42 = 74块巧克力。已经吃了35块。因此,他们总共还剩74-35 = 39块巧克力。答案是39。
Q:Jason有20个棒棒糖。他给Denny一些棒棒糖。现在Jason只有12个棒棒糖。Jason给Denny多少棒棒糖?
A:Jason有20个棒棒糖。因为他现在只有12个,所以他必须把剩下的给Denny。他给Denny的棒棒糖数量必须是20-12 = 8个棒棒糖。答案是8。
Q:Shawn有五个玩具。圣诞节,他从他的父母那里得到了两个玩具。他现在有多少个玩具?
A:他有5个玩具。他从妈妈那里得到了2个,所以在那之后他有5 + 2 = 7个玩具。然后他从爸爸那里得到了2个,所以总共他有7 + 2 = 9个玩具。答案是9。
Q:服务器房间里有9台计算机。从周一到周四,每天都会安装5台计算机。现在服务器房间里有多少台计算机?
A:从周一到周四有4天。每天都添加了5台计算机。这意味着总共添加了4 * 5 =
20台计算机。一开始有9台计算机,所以现在有9 + 20 = 29台计算机。答案是29。
Q:Michael有58个高尔夫球。星期二,他丢失了23个高尔夫球。星期三,他又丢失了2个。星期三结束时他还剩多少个高尔夫球?
A:Michael最初有58个球。星期二他丢失了23个,所以在那之后他有58-23 = 35个球。星期三他又丢失了2个,所以现在他有35-2 = 33个球。答案是33。
Q:Olivia有23美元。她用每个3美元的价格买了五个百吉饼。她还剩多少钱?
A:她用每个3美元的价格买了5个百吉饼。这意味着她花了15美元。她还剩8美元。
Q:当我6岁时,我的妹妹是我的一半年龄。现在我70岁了,我的妹妹多大?
A:
4.5 Prompt Chaining
举例-说明中,强调的问题思路是有步骤、链式的,使得下一步的结果可以引用上一步的结果,再问
你是一个很有帮助的助手。你的任务是根据文档回答问题。第一步是从文档中提取与问题相关的引文,由####分隔。请使用<quotes></quotes>输出引文列表。如果没有找到相关引文,请回应“未找到相关引文!”。
####
{{文档}}
####
输入文档
输出:
<quotes>
- Chain-of-thought (CoT) prompting[27]
- Generated knowledge prompting[37]
- Least-to-most prompting[38]
- Self-consistency decoding[39]
- Complexity-based prompting[41]
- Self-refine[42]
- Tree-of-thought prompting[43]
- Maieutic prompting[45]
- Directional-stimulus prompting[46]
- Textual inversion and embeddings[59]
- Using gradient descent to search for prompts[61][62][63][64]
- Prompt injection[65][66][67]
</quotes>
4.6 Tree of Thoughts - ToT
举例-说明中,强调的问题思路引入了一些规则(对不同的任务定义思维/步骤的数量以及每步的候选项数量),再问
适用:探索或预判战略的复杂任务
Hulbert (2023)(opens in a new tab) 提出了思维树(ToT)提示法,将 ToT 框架的主要概念概括成了一段简短的提示词,指导 LLM 在一次提示中对中间思维做出评估。ToT 提示词的例子如下:
假设三位不同的专家来回答这个问题。
所有专家都写下他们思考这个问题的第一个步骤,然后与大家分享。
然后,所有专家都写下他们思考的下一个步骤并分享。
以此类推,直到所有专家写完他们思考的所有步骤。
只要大家发现有专家的步骤出错了,就让这位专家离开。
请问...
4.7 Retrieval Augmented Generation - RAG
检索增强生成(Retrieval Augmented Generation,RAG)
输入 ==> RAG ==> 输出(相关文档) ==> LLM ==> 最终输出
要完成更复杂和知识密集型的任务,可以基于语言模型构建一个系统,访问外部知识源来做到。这样的实现与事实更加一性,生成的答案更可靠,还有助于缓解“幻觉”问题。
RAG 可以微调,其内部知识的修改方式很高效,不需要对整个模型进行重新训练。
4.8 Automatic Reasoning and Tool-use - ART
Paranjape et al., (2023)(opens in a new tab)
ART(Automatic Reasoning and Tool-use)的工作原理如下:
- 接到一个新任务的时候,从任务库中选择多步推理和使用工具的示范。
- 在测试中,调用外部工具时,先暂停生成,将工具输出整合后继续接着生成。
ART 引导模型总结示范,将新任务进行拆分并在恰当的地方使用工具。ART 采用的是零样本形式。ART 还可以手动扩展,只要简单地更新任务和工具库就可以修正推理步骤中的错误或是添加新的工具。
4.9 Automatic Prompt Engineer - APE
Large Language Models Are Human-Level Prompt Engineers
一个用于自动指令生成和选择的框架。指令生成问题被构建为自然语言合成问题,使用LLMs作为黑盒优化问题的解决方案来生成和搜索候选解。
第一步涉及一个大型语言模型(作为推理模型),该模型接收输出演示以生成任务的指令候选项。这些候选解将指导搜索过程。使用目标模型执行指令。
第二步根据计算的评估分数选择最合适的指令。
4.10 Active-Prompt
Active Prompting with Chain-of-Thought for Large Language Models
思维链(CoT)方法依赖于一组固定的人工注释范例。问题在于,这些范例可能不是不同任务的最有效示例。
用或不使用少量CoT示例查询LLM。对一组训练问题生成k个可能的答案。基于k个答案计算不确定度度量(使用不一致性)。选择最不确定的问题由人类进行注释。然后使用新的注释范例来推断每个问题。
4.11 Program-aided Language Models - PAL
它不是使用自由形式文本来获得解决方案,而是将解决步骤卸载到类似Python解释器的编程运行时中。
4.12 ReAct: Synergizing Reasoning and Acting in Language Models
LLMs 以交错的方式生成 推理轨迹 和 任务特定操作 。
- 生成推理轨迹,使模型能够诱导、跟踪和更新操作计划,甚至处理异常情况
- 操作步骤,允许与外部源(如知识库或环境)进行交互并且收集信息。
ReAct 框架允许 LLMs 与外部工具交互来获取额外信息,从而给出更可靠和实际的回应。
ReAct 提示 LLMs 为任务生成口头推理轨迹和操作。这使得系统执行动态推理来创建、维护和调整操作计划,同时还支持与外部环境(例如,Wikipedia)的交互,以将额外信息合并到推理中。
- CoT 存在事实幻觉的问题
- ReAct 的结构性约束降低了它在制定推理步骤方面的灵活性
- ReAct 在很大程度上依赖于它正在检索的信息;非信息性搜索结果阻碍了模型推理,并导致难以恢复和重新形成思想
一个实例
%%capture
# 更新或安装必要的库
!pip install --upgrade openai
!pip install --upgrade langchain
!pip install --upgrade python-dotenv
!pip install google-search-results
# 引入库
import openai
import os
from langchain.llms import OpenAI
from langchain.agents import load_tools
from langchain.agents import initialize_agent
from dotenv import load_dotenv
load_dotenv()
# 载入 API keys; 如果没有,你需要先获取。
os.environ["OPENAI_API_KEY"] = os.getenv("OPENAI_API_KEY")
os.environ["SERPER_API_KEY"] = os.getenv("SERPER_API_KEY")
llm = OpenAI(model_name="text-davinci-003" ,temperature=0)
tools = load_tools(["google-serper", "llm-math"], llm=llm)
agent = initialize_agent(tools, llm, agent="zero-shot-react-description", verbose=True)
agent.run("奥利维亚·王尔德的男朋友是谁?他现在的年龄的0.23次方是多少?")
> 正在输入新代理执行器链......
我得查出奥利维亚·王尔德的男友是谁然后计算出他的年龄的 0.23 次方。
操作: 搜索
操作输入: “奥利维亚·王尔德的男友”
观察: 奥利维亚·王尔德与杰森·苏代基斯在多年前订婚,在他们分手后,她开始与哈里·斯泰尔斯约会 — 参照他们的关系时间线。
思考: 我需要找出哈里·斯泰尔斯的年龄。
操作: 搜索
操作输入: “哈里·斯泰尔斯的年龄”
观察: 29 岁
思考: 我需要计算 29 的 0.23 次方。
操作: 计算器
操作输入: 29^0.23
观察: 答案: 2.169459462491557
思考: 现在我知道最终答案了。
最终答案: 哈里·斯泰尔斯, 奥利维亚·王尔德的男朋友, 29 岁。他年龄的 0.23 次方是 2.169459462491557。
> 结束链。
引用
- https://dev.to/pavanbelagatti/a-beginners-guide-to-building-llm-powered-applications-with-langchain-2d6e
- https://www.ionio.ai/blog/what-is-llm-agent-ultimate-guide-to-llm-agent-with-technical-breakdown
- https://zhuanlan.zhihu.com/p/642357544
- https://github.com/BradyFU/Awesome-Multimodal-Large-Language-Models
- https://lilianweng.github.io/posts/2023-06-23-agent/
- https://mp.weixin.qq.com/s/s6HQmPXbH_4no9ES3JdEug
- https://ai.meta.com/blog/retrieval-augmented-generation-streamlining-the-creation-of-intelligent-natural-language-processing-models/
- https://github.com/DSXiangLi/DecryptPrompt
- https://rapidapi.com/hub
- https://alex.macrocosm.so/download
- https://www.promptingguide.ai/zh/introduction/settings
- https://www.ainavpro.com/
- https://illa.ai/
- https://mp.weixin.qq.com/s/PL-QjlvVugUfmRD4g0P-qQ
Comments