工程经验 - 异步计算削峰方案 & 实战
一、背景
我们的产品曾服务于科研行业厂商,为其提供 AI 训练和数据计算功能。其中一个重要功能是【指标计算】:
- 用户提交指标文件
- 后端读取文件并进行分数计算
- 用户可以在提交列表中查看提交记录,其中包括计算指标和各项分数
二、问题
根据需求,我们使用算法工程师提供的 SDK 对计算性能进行边界测试。然而,我们发现计算时间非常长,可能需要几分钟,甚至几小时的时间。从工程角度来看,此需求需要进行异步化处理。因此,我们的负责计算服务的同事提供了一个异步的 gRPC 接口,计算结果会以 MQ 的方式发布。
后来,我们成功地完成了这个功能,并对其进行了性能边界测试。然而,我们发现计算非常耗费资源。在进行 1 个 50 万行数的文件或者 5 个 10 万行数的文件计算时,就会导致内存溢出,计算失败。
通常,用户提交的文件规模在 10 万行左右。由于生产环境的机器配置大约是研发环境的 4 倍,因此意味着如果有 20 个用户同时提交计算请求,服务就会崩溃。
三、初版方案 - 客户端内存队列
为了解决并发计算导致内存溢出问题,我们决定在客户端(也就是业务服务)这一侧,临时采用一个内存队列方案,其中所有的内存队列均为 BlockingQueue。
我们的整体方案如下:
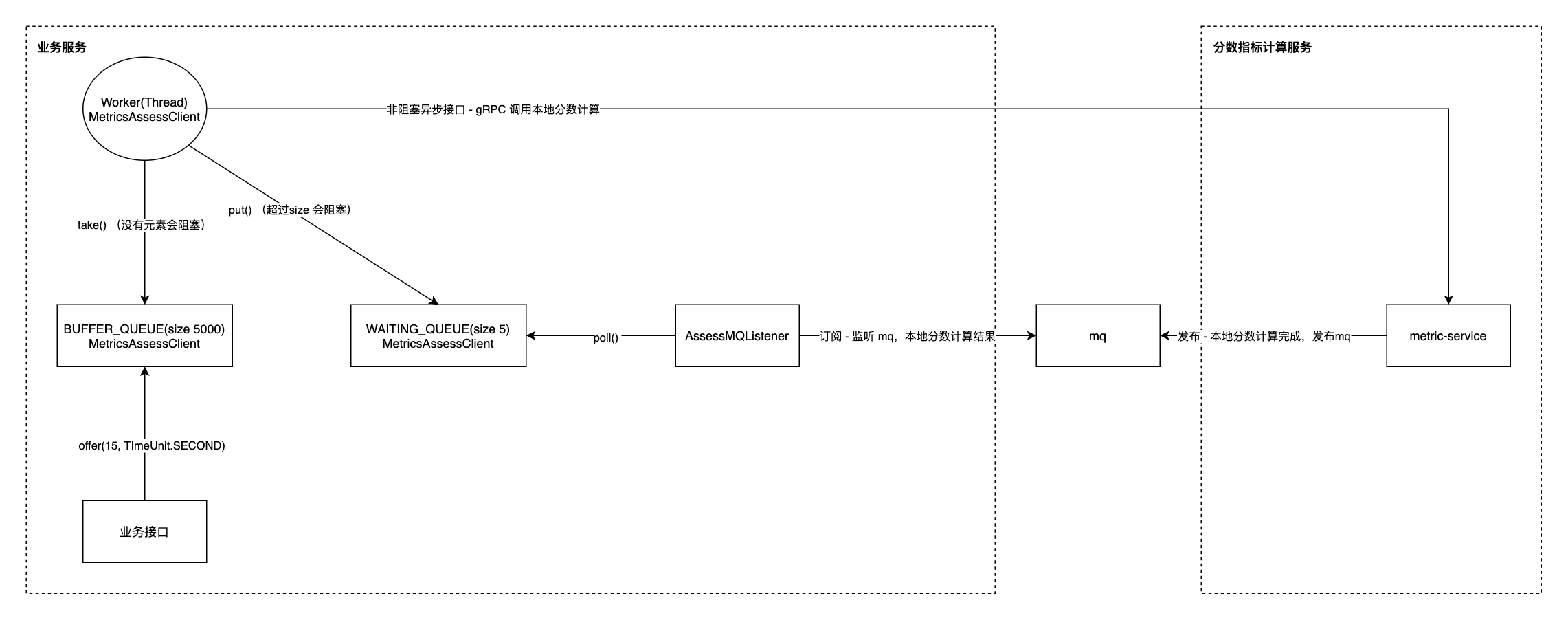
业务服务:
- 业务接口接收请求参数,并将其放入缓冲队列中。如果缓冲队列已满,则返回超时错误。缓冲队列最多存储 5000 个请求
- 建立一个工作线程,从缓冲队列中取出参数,并将其放入等待队列中。等待队列最多存储 5 个请求
- 工作线程每成功放入一个请求到等待队列中,就会调用一次分数计算服务进行计算
- 监听 MQ 并订阅计算结果
分数指标计算服务:
- 新建进程进行分数计算,并在计算完成后将结果发布到 MQ
该方案存在以下缺点:
- 复杂度高:手动实现队列进行限流,增加了代码的复杂度和维护难度
- 数据丢失:服务重启时,内存队列中的数据会丢失,无法继续处理
四、优化方案 - MQ 队列
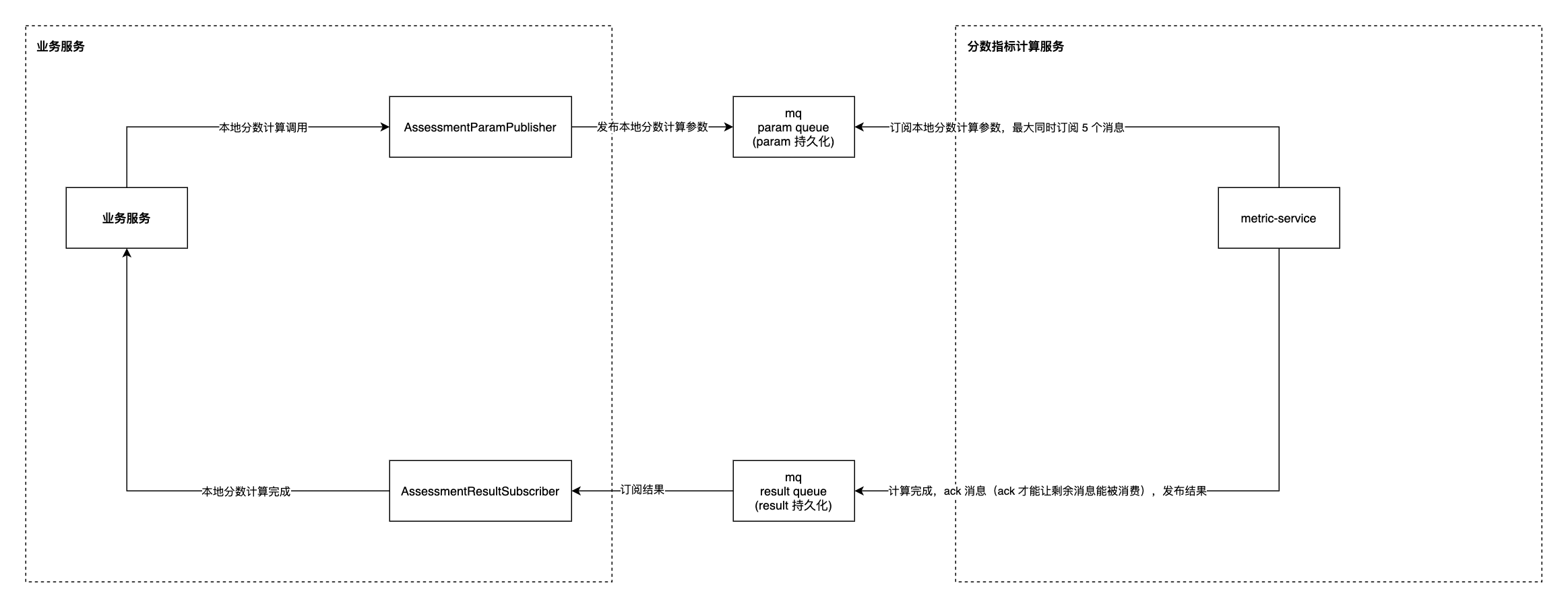
业务服务
业务接口触发指标提交时,使用发布者向参数队列发布一个参数
/**
* 定义参数队列
*/
@Configuration
public class AssessmentMQConfig {
/**
* 参数队列,第二个参数 true 表示开启持久化
*/
@Bean
public Queue paramQueue() {
return new Queue(PARAM_QUEUE, true);
}
/**
* 结果队列,第二个参数 true 表示开启持久化
*/
@Bean
public Queue resultQueue() {
return new Queue(RESULT_QUEUE, true);
}
}
@Component
@RequiredArgsConstructor
public class ParamPublisher {
private final AmqpTemplate rabbitTemplate;
public void publish(String s) {
rabbitTemplate.convertAndSend(PARAM_QUEUE, s);
}
}
业务服务监听结果队列,取到参数之后更新数据库,从而让用户查询获取到结果。ACK 注意 - 这里是更新完数据库了,再 ACK 计算结果
@Slf4j
@Component
@RequiredArgsConstructor
public class ResultSubscriber {
@RabbitListener(queues = AssessmentMQConfig.ASSESSMENT_RESULT_QUEUE)
public void processData(String result, Channel channel, @Header(AmqpHeaders.DELIVERY_TAG) long deliveryTag) throws IOException {
log.info("从队列订阅到消息:[{}]", result);
try {
// update message in db
} catch (Exception e) {
// 捕捉异常,防止消息无法被 ack
log.error(e.getMessage(), e);
}
// ack 消息
channel.basicAck(deliveryTag, true);
}
}
分数指标计算服务
定义参数监听逻辑,ACK 注意 - 这里是计算完成,结果发布到结果队列了,再去 ACK 参数
@Slf4j
public class MetricsService {
public void listenAndCalculate() {
Channel channel = MqManager.getChannel();
try {
channel.basicConsume(
PARAM_QUEUE,
// auto ack false
false,
// 注册处理逻辑
new ParamSubscriber(channel)
);
} catch (IOException e) {
log.error(e.getMessage(), e);
}
}
}
定义结果发布逻辑,可以看到无论是参数队列或者结果队列最后对会绑定到 Channel ,Channel 会和一个 Connection 绑定,对 Channel 进行了关键参数 basicQos 的配置,使得从队列获取消息时,消费完了 basicQos 数量的参数,才会取下一批
public class MqManager {
private static Channel channel;
private static void setupChannel() throws IOException {
// 关键参数 - 声明队列的监听一次性最多监听 5 个
channel.basicQos(5);
// 声明结果队列的交换机、队列、交换机绑定
channel.exchangeDeclare(RESULT_FANOUT, BuiltinExchangeType.FANOUT, true);
// 第二个参数为 true,表示此队列持久化
channel.queueDeclare(RESULT_QUEUE, true, false, false, null);
channel.queueBind(RESULT_QUEUE, RESULT_FANOUT, ROUTE_KEY);
}
public static Channel getChannel() {
return channel;
}
public static void resultPublish(String message) throws IOException {
if (channel == null) {
initConnection();
}
channel.basicPublish(RESULT_FANOUT, ROUTE_KEY, null, message.getBytes(StandardCharsets.UTF_8));
}
}
该方案采用 MQ 和手动 ACK,实现了参数和结果的解耦和持久化,从而保证了业务处理数据的一致性。
- 如果业务服务重启,业务接口的参数在队列中不会丢失,而且在处理到一半时如果没有 ACK,重启后仍然可以监听到。这保证了参数的可靠性和一致性
- 如果 MQ 重启,由于参数和结果都已经持久化,启动后可以再次被处理
- 如果计算服务重启,参数可以重新从队列中监听到,重新开始计算。同时,已经计算成功的结果会被发布到结果队列中,这不会影响后续处理
综上,此方案可以有效地解决业务处理数据的一致性问题,并提高了系统的可靠性
Comments