HTTP 原理与实战 - 报文分析
学会抓包后,也对 HTTP 有了个大概的了解了,本篇深入 HTTP 的报文(HTTP/1.1),看看里面都是什么东西,最后总结一下对这个协议的理解
一、组成
HTTP 协议的报文,和 TCP/UDP 不同的是,它是一个“纯文本” 协议,所以它的报文数据是可以肉演读懂的,而 TCP/UDP 报文数据是二进制流数据
HTTP 协议的请求报文和响应报文结构基本相同,三大部分组成:
- 起始行(start line):描述请求或响应的基本信息
- 头部字段集合(header field):使用 k-v 形式详细说明报文内容
- 消息正文(entity):实际传输的数据,不一定是纯文本,可以是图片、视频(它们的二进制格式数据)
起始行和头部字段常被称之为 请求头 或 响应头 :request header / response header,简称为 header
消息正文常称之为 实体:request body / response body,简称为 body
而 header 和 body 之间,会有一行空行,是 CRLF 这个字符表示的
因此,HTTP 的报文组成就是:
- header
- 空行
- body
看看之前 wireshark 抓包的数据,查看 TCP 连接后浏览器发送的 HTTP GET 请求:
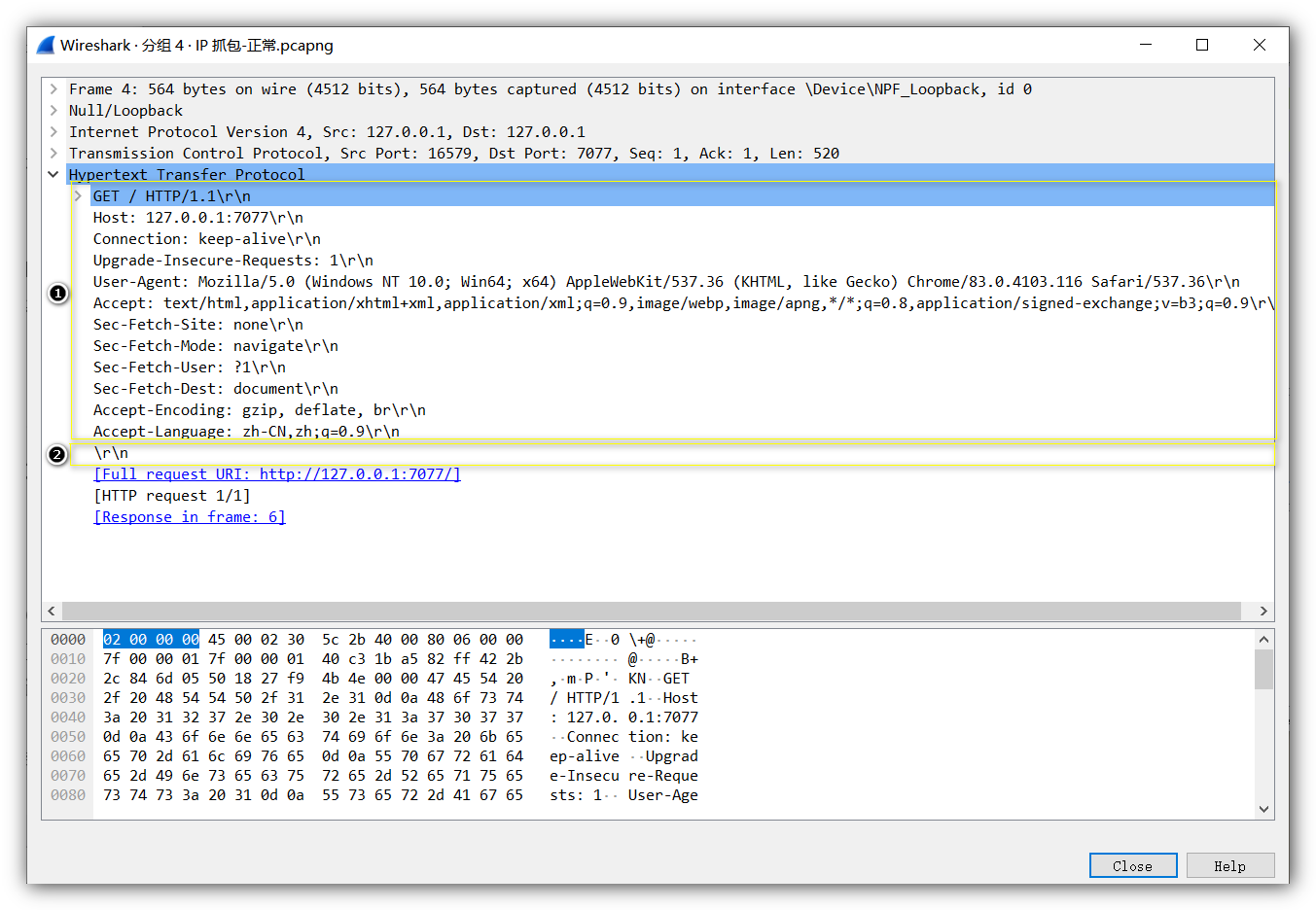
- 标注 1 就是 header
- 标注 2 就是空行
可以发现没用 body,HTTP GET 请求中经常这么干,不会发送 body 数据
二、请求行
从上一小节知道,请求行是 header 的一部分,它的组成如下:
- 请求方法,例如 GET / POST,表示对资源的操作
- 请求目标,通常是一个 URI ,表示请求方法要操作的资源
- 版本号,表示使用的 HTTP 的版本
在请求行中,这三个部分通常使用空格(space)来分割,最后要用 CRLF 换行表示结束
GET / HTTP/1.1\r\n
三、状态行
状态行就是响应报文的起始行,但它不叫响应行,叫状态行,表示服务器响应的状态,它的组成如下:
- 版本号:表示使用的 HTTP 版本
- 状态码:一个三位数,用代码的形式表示处理的结果,例如 200
- 原因:作为数字状态码补充,是更详细的解释文字,可以让人们更好理解原因
状态行和请求行的分割格式一样,空格,CRLF:
HTTP/1.1 200 OK\r\n
四、头部字段
规范
头部字段是 key:value 这样的形式表示的,最后要用要给 CRLF 换行表示字符结束,也就是 \n\r ,比如 Connection:keep-alive\r\n
规范:
- 字段名不区分大小写,但 key 首字母大写的可读性更好
- 字段名不允许出现空格,可以使用
-或者_,例如,字段可以写:Temp_num:123 - 字段的 k 与 v 之间使用
:连接,且不能有空格,错误示范例如:Temp_num : 123 - 字段的顺序是没用意义的,可以任意排列
- 字段原则上不能重复,除非这个字段本身语义允许,例如 Set-Cookie
常用头部字段
Host
请求字段,唯一一个 HTTP/1.1 规范要求必须出现的字段,没用该字段,报文肯定是错误的。该字段告诉服务器请求应该用哪个主机来处理,因为一个 IP 是可以被多个域名映射的,必须得选择一个域名代表的主机处理请求
User-Agent
请求字段,使用一个字符串来描述发起 HTTP 请求的客户端,服务器可以根据它返回最合适此浏览器显示的页面,例如,值可能是 “Mozilla”、“Chrome”、“Safari” 等,爬虫有的会在这标注 “spider”
Date
通用字段,通常在响应头,表示 HTTP 报文创建时间,客户端可以根据此字段配合其他字段制定缓存策略
Server
响应字段,它告诉客户端当前正在提供 Web 服务的服务器软件的名称和版本号,例如:Server: openresty/1.17.8.1,这也是可以不用描述的,不对外公布服务器信息,可以增加一定的安全性
Github 就没有写出具体的信息
Content-Length
通用字段,表示报文的 body 的长度,如果没用该字段,body 就是不定长的,那么传输时需要使用 chunked 分块传输
五、请求方法
常用方法
- GET
- HEAD
- POST
- PUT
GET / HEAD
GET 含义是从服务器获取资源
它是从 0.9 开始就保留至今的元老,可以用于获取各种静态的文本、页面、图片、视频,也可以是 Java 一类动态生成的页面或者其他格式的数据
在 GET 中,URI 后使用 # ,额可以获取页面后直接定位到某个表现所在的位置
使用 If-Modified-Since 字段就变成了 “有条件的请求”,仅当资源被修改时才会执行获取动作
使用 Range 字段就是 “范围请求” ,只获取资源的一部分数据
Head 和 GET 是一样的功能,但不会返回 body 部分的数据,只会传回响应头,也就是资源的 “元信息“
发送 GET 与 HEAD ,对同一 URI 的响应头是一致的,基于 Telnet 做测试如下:
-
启动 openresty
-
启动 telnet
-
分别发送两个请求
GET /10-1 HTTP/1.1 Host: www.chrono.com HEAD /10-1 HTTP/1.1 Host: www.chrono.com -
可以发现获取到的结果是一致的

POST / PUT
POST / PUT 含义是往服务器推送数据
它可以向 URI 指定的资源提交数据,数据就放在报文的 body 中
PUT 的作用和 POST 是类似的,可以向服务器提交数据,但与 POST 有一些微妙的不同,POST 表达 ”新建“ 的意思,而 PUT 表达 ”更新“ 的意思
由于 PUT 与 POST 实在类似,有的服务器直接禁用了 PUT,只使用 POST 上传数据
PUT 与 POST 都可以推送数据,基于 Telnet 做测试如下:
-
启动 openresty
-
启动 telnet
-
发送两个请求
-
分别发送两个请求
POST /10-2 HTTP/1.1 Host: www.chrono.com Content-Length: 17 POST DATA IS HERE PUT /10-2 HTTP/1.1 Host: www.chrono.com Content-Length: 16 PUT DATA IS HE -
可以发现,服务器分别响应了 body 的数据,两个请求成功向服务器推送了数据

非常用方法
- DELETE
- CONNECT
- OPTIONS
- TRACE
DELETE
DELETE 的含义是让服务器删除指定的资源,一般服务器不会真正删除,而是标记资源为”已删除“,很多时候服务器就直接不处理 DELETE 请求
CONNECT
CONNECT 的含义是要求服务器和另一台远程服务器建立一条特殊的连接隧道,此时 Web 服务器在中间充当了代理的角色
OPTIONS
OPTIONS 的含义是要求服务器列出可对资源始行的操作方法,在响应头的 Allow 字段返回,由于普通应用不是很多,有的服务器(例如 Nginx)没实现对它的支持
但 CORS 跨域请求就必须用到 OPTIONS 方法了
Trace
Trace 的含义是显示出请求 - 响应的传输路径。它可以用于对 HTTP 链路的测试或诊断,由于存在漏洞会泄漏网站的信息,所以 Web 服务器通常是禁止使用
扩展方法
- MKCOL
- COPY
- MOVE
- LOCK
- UNLOCK
- PATCH
HTTP/1.1 规定了标准八种请求方法,但它并没有限制我们只能用这八种,我们自己还能任意添加请求动作,只要请求方和响应方都能理解就行
于是,这些请求动作就是非标准方法,也就是自己的扩展方法
而以上列出的几种方法就是已经得到了实际应用的请求方法(WebDAV):
- LOCK 指的是锁定资源暂时不允许修改
- PATCH 方法是给资源打个补丁,部分更新数据
值得注意的是,就算以上的扩展方法得到了业界的应用,但它们是非标准的。客户端和服务器都要写一些额外的定制代码,才能支持这些非扩展方法
对于这些语义上的扩展方法,我们根据自己的需求还能发明自己的扩展方法:
- PULL:定制其动作和含义为拉取某些资源到本地
- PURGE:清理某个目录下的所有缓存数据
幂等性
幂等性是一个数学的概念,对于 HTTP 就是多次执行相同的操作,服务器端的结果都是相同的
幂等性的方法(这些不改变服务器状态):
- GET
- HEAD
- DELETE(删除一次后,后面的效果都是”资源不存在“)
非幂等的方法(每次都会改变服务器状态):
- POST:把它理解成 SQL 的 INSERT。多次提交,会创建多个资源,服务器的结果不一致
- PUT:把它理解成 SQL 的 UPDATE。多次提交,会多次更新一个数据,服务器的结果不一致
六、请求 URL
基本组成
组成的通式:scheme://host:port path?query
scheme:方案名,协议名,表示资源应该使用哪种协议来访问,例如 ftp、ldap、file、news、https
host:port:主机和端口,端口有时可以省略,例如 HTTP 的默认端口 80,HTTPS 的默认端口 443
path:就是资源所在位置的 path,浏览器可以连接服务器访问资源
实例
http://nginx.org
- 协议 http
- 主机名 nginx.org
- 端口号省略,默认是 80
- 路径部分省略,默认是 /,表示根目录
file:///D:/http_study/www/
- 协议 file
- 主机名省略,默认是 localhost,紧接着使用 / 连接路径
- 端口号省略,协议不要求
- 路径是 D:/http_study/www/
七、请求实体
数据类型
起源于 多用途互联网邮件扩展”(Multipurpose Internet Mail Extensions),简称为 MIME,该协议可以让电子邮件可以发送 ASCII 码以外的任意数据
HTTP 取其中的一小部分,用来标记 body 的数据类型,这就是我们平时总能听到的 MIME type
MIME 把数据分成了八大类,每个大类下再细分成多个子类,形式是 ”type/subtype“ 的字符串
常见的类别:
- text:即文本格式的可读数据,我们最熟悉的应该就是 text/html 了,表示超文本文档,此外还有纯文本 text/plain、样式表 text/css 等。
- image:即图像文件,有 image/gif、image/jpeg、image/png 等。
- audio/video:音频和视频数据,例如 audio/mpeg、video/mp4 等。
- application:数据格式不固定,可能是文本也可能是二进制,必须由上层应用程序来解释。常见的有 application/json,application/javascript、application/pdf 等,另外,如果实在是不知道数据是什么类型,像刚才说的“黑盒”,就会是 application/octet-stream,即不透明的二进制数据。
压缩
HTTP 传输的时候为了节约带宽,还会压缩数据,为了不让浏览器继续”猜“,需要有一个 ”Encoding type“(头部字段),告诉数据是用什么编码格式,这样对方才能正确压缩,还原出原始的数据
常见的三种:
- gzip:GNU zip 压缩格式,也是互联网上最流行的压缩格式;
- deflate:zlib(deflate)压缩格式,流行程度仅次于 gzip;
- br:一种专门为 HTTP 优化的新压缩算法(Brotli)。
内容协商
MIME type 和 Encoding type ,可以让客户端或者浏览器轻松识别出 body 的类型,从而处理数据
除此之外,HTTP 还制定了:
- 请求的头部字段
- Accept
- Accept-Encoding
- 响应的头部字段
- Content-Type
- Content-Encoding
任意 Content-* 类型的字段用在请求头也是可以的,用于说明请求体的数据类型
这样的一组字段来进行内容协商,客户端用 Accept 告诉服务端希望接收的数据,服务端用 Content 告诉客户端实际发送了什么样的数据
实例,客户端想要图片,并且格式是压缩的:
客户端
Accept: text/html,application/xml,image/webp,image/png
Accept-Encoding:gzip, deflate, br
服务端
Content-Type: image/png
Content-EnCoding: gzip
值得注意的是,如果请求报文里没有 Accept-Encoding,表示客户端不支持压缩数据,响应报文没有 Content-Encoding,表示数据没有被压缩
内容协商还可以用 q (quality factor)来值得优先级,越大越高
,例如:
Accept: text/html,application/xml;q=0.9,*/*;q=0.8
它表示浏览器最希望使用的是 HTML 文件,权重是 1,其次是 XML 文件,权重是 0.9,最后是任意数据类型,权重是 0.8。服务器收到请求头后,就会计算权重,再根据自己的实际情况优先输出 HTML 或者 XML。
八、状态码
状态码是我们的老朋友了,这是服务器响应给客户端的响应报文必须带上的一个东西:
- 1××:提示信息,表示目前是协议处理的中间状态,还需要后续的操作;
- 2××:成功,报文已经收到并被正确处理;
- 3××:重定向,资源位置发生变动,需要客户端重新发送请求;
- 4××:客户端错误,请求报文有误,服务器无法处理;
- 5××:服务器错误,服务器在处理请求时内部发生了错误。
RFC 标准里总共有 41 个状态码,状态码的定义是开放的,可以自行扩展,所以 Apache、Nginx 等 web 服务器都定义了一些专有的状态码,
1xx
常见的有 "101 Switching Protocols",场景可能是:
- 客户端使用 Upgrade 头,要求在 HTTP 协议的基础上改成其他的协议继续通信,比如 WebSocket
- 服务端同意变更该协议,发送状态码 101 ,此后便只用 Upgrade 指定的协议
2xx
- 200 OK,常见的成功状态码
- 204 No Content,响应并且没有 body 数据
- 206 Partial Content,HTTP 分块下载或断点续传的基础,body 里的数据是要响应的全部数据的一部分,常与 Content-Range (请求字段)配合使用,例如 Cotent-Range: bytes 0-99/2000 ,表示总共 2000 字节,此次要获取前 100 个字节
3xx
- 301 Moved Permantyly,永久重定向,客户端需要改用新的 URI 再次访问,例如网站从 HTTP 升级到 HTTPS ,要使用这个重定向
- 302 Not Found,临时重定向,与 301 一样,只是语义上的区别,例如网站后台今晚维护,可以指定 302 重定向到临时的服务器提供给客户端
- 304 Not Modified,缓存重定向,客户端需要带上
If-Modified-Since字段做请求,如果服务器响应该状态码,表示资源没有修改,相当于重定向到缓存了、
4xx
- 400 Bad Request,一个通用的状态码,表示请求报文有错
- 403 Forbidden,服务器禁止客户端访问
- 404 Not Found,资源在服务器上未找到
5xx
- 500 Internal Server Error,服务器内部错误
- 501 Not Implemented,客户端请求的功能还不支持
- 502 Bad Gateway,服务器作为网关或者代理时返回的错误码
- 503 Service Unavailable,服务器当前很忙,暂时无法响应服务,通常 503 响应报文会有一个 "Retry-After" 字段
九、总结
HTTP 简单通用
了解了 HTTP 的报文后可以发现,这个协议支持许多特性:头部字段、实体数据、连接控制、缓存代理。它是一个几乎可以传递任意数据的协议
与 HTTP 同样作为应用层协议的有 FTP (文件传输)、SMTP(邮件传输)、SSH(远程连接)
那么使用 HTTP 是否也可以实现这些应用层协议的功能?答案是可以的,只要双方协定好相关的规则即可
所以,HTTP 真的是一个非常通用的协议
但有两点要注意:
-
一方面,使用 HTTP 协议做文件传输的效率肯定不如类似 FTP 这种专门的针对一种业务场景的数据
-
还有一点是如果使用 HTTP 做文件传输,那么还得专门定制一套对应的传输规则
举个例子,客户端这边,文件可能按照接口协议好,转成二进制字符串,放 body 里传输,服务端则是按照协定好的规则对这个二进制字符串反序列化为文件,做这个过程的可靠性和复杂性还不如直接用 HTTP,性能也是问题
HTTP 由于它的简单强大,被外界广泛使用,而由于性能与复杂度,它也无法取代许多应用层的老牌协议
无状态
可以看到全文并没有涉及到状态,HTTP 是无状态,不像 TCP 是有状态协议,TCP 连接管理时,是有许多状态的,此时它的连接管理是靠着两方的状态来判断是否正常
而 HTTP 通信的两方没有记住彼此的状态,一次请求-应答,就完事了
无状态的好处:
- 服务器负载变小,可以专注于客户端的请求处理,不用管它的状态信息
- 服务器容易组成集群,因为任意一台服务器对客户端来说都是一样的,没有状态
无状态的坏处:
服务端无法连续进行多个状态相同的操作,例如,一个用户做三件事:登录、结算,支付,客户端的用户状态是一样的,服务器却无法知道,每件事做之前都得与用户做一次认证,是不是同一个用户。其实如果确定了用户状态就是同一个用户,那可以直接执行这三件事
不安全
- 明文传输数据,报文的内容是可见的,不像 TCP 是字节流,所以 HTTP 不安全
- 没有身份认证,无法确定通信双方的真是身份
- 不支持完整性校验,数据被改了,接收方也不知道到底有没有被改,虽然可以使用 MD5 给报文加数字摘要,但如果抓包的连数据摘要也改了,那就判断不出数据完整性了
性能中庸
基于 TCP ,这个协议性能不错,但上层的模式是基于请求-应答,会出现队头阻塞问题:Head-of-line blocking,顺序发送的请求序列钟一个请求因为某种原因被阻塞时,后面排队的请求也一并被阻塞,客户端就会一直收不到数据
在 HTTP/2 和 HTTP/3 有相应的解决方案
Comments