RAG 工程:从容应对增量数据 - 解读 ERA-RAG 设计
最近在为组内的需求做技术调研,在看看 RAG 领域相关的工作。
上一篇我们回顾了经典 RAPTOR 的设计,本次我们接着看看 ERA-RAG 相关的设计思路,这篇文章目前看着没有在任何会议 / 期刊发布,但由于被 RAGFLow 写进了 25 年和 26 年的 ROADMAP,所以可能还是值得一看的。
传统的 RAG(检索增强生成)技术,虽然能让大模型(LLM)用上外部知识库,解决“一本正经地胡说八道”的问题,但它有个致命的弱点:大部分 RAG 系统都假设知识库是静态的,不怎么变。
一旦知识库开始“生长”,比如每天都有一堆新文档进来,这些系统就抓瞎了。最头铁的办法就是推倒重来,把整个知识库重新处理一遍,建个新的索引。这计算开销,放谁身上都顶不住,又耗时又费钱。这就好比一本字典,每增加一个新词,你就得把整本字典重新印刷一遍,太离谱了。
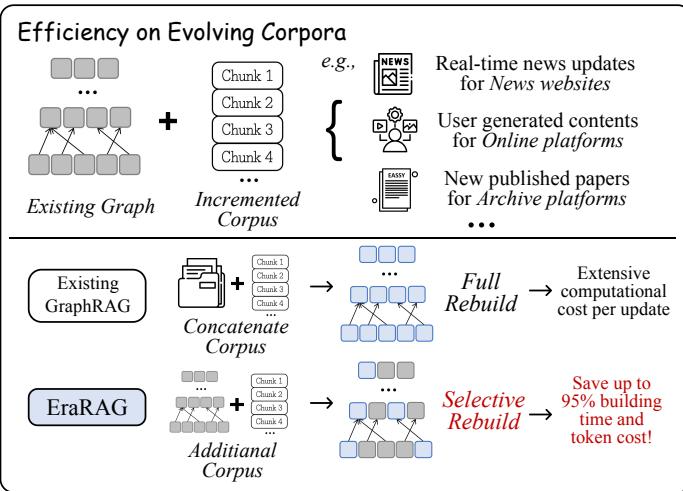
今天,咱们要聊的这篇论文《EraRAG》,就是要干掉这个痛点。它提出了一套全新的 Graph-RAG 框架,主打的就是一个高效和增量更新。新文档来了?不用慌,哪里变了就只更新哪里,其他地方纹丝不动。这使得它在动态、持续增长的知识库场景下,表现得极其优雅。
一、RAG 发展:从“一盘散沙”到“井井有条”
1.1 朴素 RAG:简单直接,但有点糙
最早的 RAG,我们称之为“朴素 RAG” (Vanilla RAG),思路非常简单粗暴,分三步走:
- 预处理(Indexing):先把你的知识库(比如一堆 PDF、Word 文档)切成一小块一小块的文本,我们管这些小块叫“块”(Chunks)。然后,用一个叫做“嵌入模型”(Embedding Model)的东西,把每个 Chunk 都转换成一个高维向量(Vector)。你可以粗略地把这个向量理解成这个 Chunk 在“语义空间”里的坐标。最后,把这些向量和原始文本一起,塞进一个向量数据库里。
- 检索(Retrieval):当用户提问时,我们用同样的 Embedding Model 把问题也转换成一个向量。然后拿着这个“问题向量”,去向量数据库里找跟它“距离”最近的 Top-K 个 Chunk 向量。这里的“距离近”,通常就是指语义上最相关。
- 生成(Generation):把用户原始的问题,和上一步检索到的 Top-K 个 Chunks,一起“打包”成一个提示(Prompt),然后喂给大语言模型(LLM)。LLM 就会参考这些检索到的内容,生成一个既包含知识又回答了问题的答案。
这个流程下来,LLM 就好像有了一本可以随时翻阅的参考书,回答的准确性自然就上去了。
但是,这种朴素 RAG 有个明显的问题:检索回来的 Chunks 可能是语义重复或者毫无关联的“散装知识”。比如问一个复杂问题,可能需要从 A 文档找个概念,再从 B 文档找个案例,朴素 RAG 很难保证能同时、并有逻辑地把它们都找出来。找回来的东西可能在语义上很接近问题,但内在缺少逻辑联系,就像一盘散沙,LLM 想把它们串起来生成一个有深度、有逻辑的答案,就比较吃力了。
1.2 Graph-RAG:给知识建立“关系网”
为了解决朴素 RAG 的“散沙”问题,更高级的玩法——Graph-RAG 登场了。
它的核心思想是:在预处理阶段,就不仅仅是简单地把文档切块、向量化,而是要分析这些 Chunks 之间的内在联系,构建成一个图(Graph)结构。
这个图里,节点(Node)可以是单个的 Chunks,也可以是多个 Chunks 的摘要(Summary)。而边(Edge)则表示节点之间的关系,比如“相似”、“引用”、“从属”等等。通过这种方式,我们把零散的知识点组织成了一张巨大的、有结构的“知识网络”。
这么做的好处是什么呢?
- 减少冗余:如果几个 Chunks 讲的是同一个意思,可以在图里把它们聚合成一个摘要节点,检索时直接拿摘要就行了,简洁高效。
- 上下文更连贯:检索时,我们不仅可以找到和问题最相关的节点,还可以顺着图的边,找到它的“邻居”节点。这些邻居节点提供了宝贵的上下文信息,让检索回来的知识更加连贯和完整。
- 支持多跳推理(Multi-hop Reasoning):对于复杂问题,答案可能散落在知识库的不同角落。Graph-RAG 可以从一个相关节点出发,沿着图的路径“跳”几下,把分散的知识串联起来,形成一条完整的证据链。这是朴素 RAG 很难做到的。
目前市面上一些比较火的 Graph-RAG 方法,比如 RAPTOR,就是通过递归聚类和摘要的方式,构建了一个层次化的图结构。底层是原始的 Chunks,往上是第一层摘要,再往上是更高层次的摘要,形成一个金字塔结构。这种结构既能支持细粒度的细节查询,也能支持高层次的宏观理解。
1.3 现有 Graph-RAG 的致命弱点
Graph-RAG 看起来很美好,但在一个关键场景下却显得力不从心——动态变化的知识库。
想象一下我们的系统每天都要接入成百上千篇新的行业报告。对于 RAPTOR 这类方法,它们的图构建过程是“一次性”的。比如,RAPTOR 使用的聚类算法(如 UMAP + HDBSCAN)在每次运行时,结果都可能不一样,具有不确定性。这意味着,只要有新文档进来,为了维持整个图的结构和语义一致性,它别无选择,只能把所有新旧文档混在一起,从头到尾重新跑一遍聚类、摘要和建图的流程。
这开销有多大?看下面这张图就知道了。横轴是数据插入的轮次,纵轴是消耗的 Token 数和时间。可以看到,像 GraphRAG 和 RAPTOR 这样的方法,每加一点新数据,成本就往上涨一大截,因为它们在做大量的重复计算。
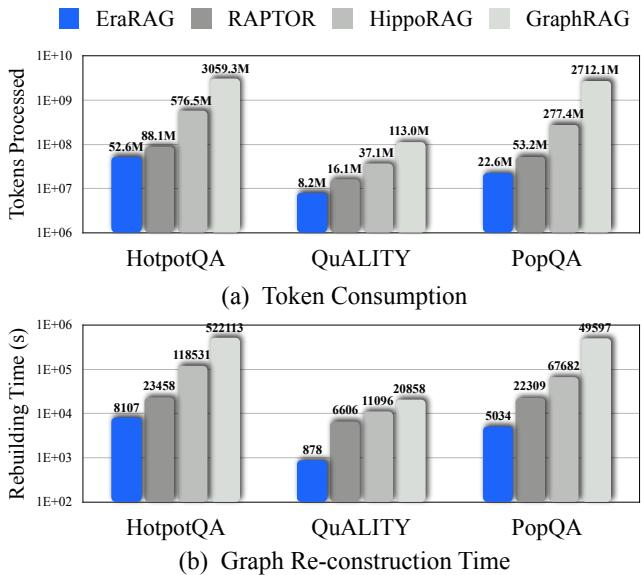
注:不同方法在增量更新时的 Token 消耗和时间成本
对于需要高频更新知识库的真实世界应用来说,这种“全量重建”的模式是完全不可接受的。效率低下、成本高昂,是悬在现有 Graph-RAG 头上的“达摩克利斯之剑”。
而 EraRAG,就是为了斩断这把剑而生的。它的核心目标,就是在享受 Graph-RAG 带来的高质量检索的同时,还能实现对动态知识库的高效、低成本的增量更新。
二、EraRAG 的核心武器:可复现的分桶术
EraRAG 的整体架构看起来很复杂,但核心思想其实非常精妙。它通过一套巧妙的机制,实现了图的高效构建和“外科手术式”的精准更新。我们先来看它的整体架构图,然后一步步把它拆解开。
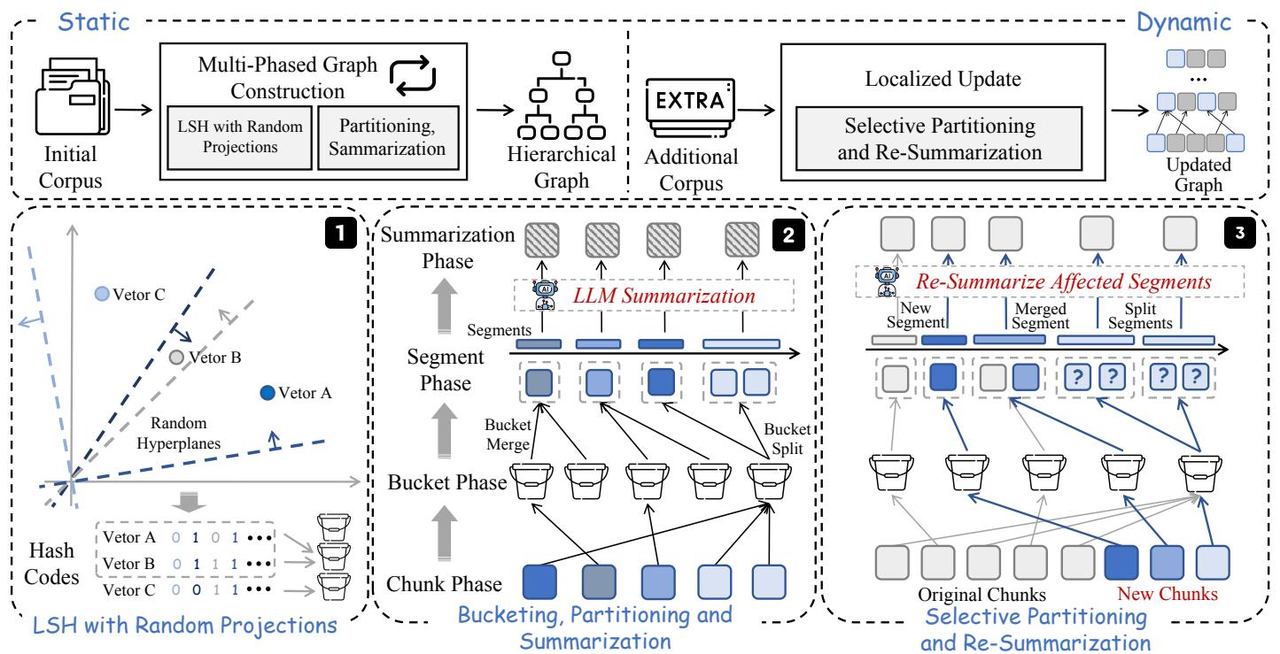
这张图分了三个部分:
- 分层图构建 (Hierarchical Graph Construction):这是静态构建的阶段,把初始知识库建成一个层次化的图。
- 查询处理 (Query-time Search):用户提问时如何在这个图里检索。
- 增量更新 (Incremental Updates):当新文档进来时,如何高效地更新这个图。
咱们先从最基础、也是最关键的第一部分讲起。EraRAG 能够实现增量更新的基石,在于它采用了一种可复现的分组方法。
2.1 LSH:高维世界的“就近分组”法
在构建图的第一步,我们需要把语义上相似的 Chunks 聚在一起。传统的聚类算法(比如 K-Means 或 RAPTOR 用的 UMAP+HDBSCAN)虽然效果好,但通常是“黑盒”且不稳定的,数据稍有变动,聚类结果可能天差地别。
EraRAG 另辟蹊径,选择了一个经典而高效的算法:局部敏感哈希(Locality-Sensitive Hashing, LSH)。
LSH 的核心思想很简单:设计一种特殊的哈希函数,能让原本相似的(在高维空间里距离近的)数据,以很高的概率被哈希到同一个“桶”(Bucket)里;而原本不相似的数据,则很大概率被分到不同的桶里。
这就好比一个神奇的分类帽,能自动把性格相似的学生分到同一个学院。
EraRAG 具体用的是一种基于**随机超平面(Random Hyperplane)**的 LSH 方法。这个方法非常直观。
想象一下我们的 Chunk 向量都分布在一个高维空间里。现在,我们在这个空间里随机地画一条线(二维空间)、一个平面(三维空间),或者一个“超平面”(更高维空间)。这个超平面会把整个空间一分为二。
- 所有在超平面一侧的向量,我们给它们标记为 1。
- 所有在另一侧的向量,我们给它们标记为 0。
这样,一个超平面就能产生一个 1 bit 的哈希值。
如上图左侧部分所示,我们不只用一个超平面,而是用 k 个随机超平面来“切割”这个空间。每个向量 v 都会和这 k 个超平面逐一进行比较(具体来说是做点积运算,v · h > 0 则为1,否则为0)。这样,每个向量就能得到一个 k 位的二进制哈希码(hash code)。
hash(v) = [sign(v·h₁), sign(v·h₂), ..., sign(v·hₖ)]
这个 k 位二进制码,就是这个向量所属的“桶”的ID。
为什么这个方法能把相似的向量分到一起呢?因为如果两个向量 v₁ 和 v₂ 的夹角很小(也就是它们在语义上很相似),那么它们同时落在某个随机超平面同一侧的概率就很高。经过 k 次这样的“投票”,它们最终得到相同或非常相似的哈希码的概率也就非常大。
2.2 EraRAG 的点睛之笔:保存超平面
传统 LSH 的用法是,哈希完了就完了,主要用于快速近似查找。但 EraRAG 做了一个看似微小却极其关键的操作:它把第一次建图时随机生成的那 k 个超平面给保存了下来!
这一下就解决了聚类结果的“不确定性”问题。
因为超平面是固定的,所以整个哈希过程就变成了一个确定性的、可复现的过程。
- 对于初始数据:把所有 Chunks 向量化,用这组固定的超平面计算出各自的哈希码,分到对应的桶里。
- 对于新来的数据:同样,向量化后,用同一组超平面去计算哈希码。这样,新来的 Chunk 就会被确定地分配到它应该去的那个桶里,而不会影响到其他桶的成员。
这就好比我们有了一套固定不变的“测量标准”(这些超平面)。无论什么时候来一个新物件,我们都用同一把尺子去量它,得出的结果自然是可以比较和归类的。
这个“保存超平面”的设计,是 EraRAG 能够实现高效增量更新的根本基石。 它确保了分组过程的可复现性,使得局部更新成为可能。
2.3 从“桶”到“段”:Merge & Split 策略
通过 LSH,我们把 Chunks 分进了不同的“桶”。但是,这些桶的大小可能非常不均匀。有的桶因为处在语义密集的区域,可能挤进来了成百上千个 Chunks;而有的桶可能地处“偏远”,只有寥寥几个。
如果直接对这些大小不一的桶进行摘要,会产生两个问题:
- 摘要质量不可控:对几千个 Chunks 做摘要和对几个 Chunks 做摘要,生成的摘要粒度完全不同,质量也难以保证。
- 图结构不均衡:摘要节点代表的知识粒度忽大忽小,会导致整个层次图结构不均衡,影响后续的检索效率和效果。
为了解决这个问题,EraRAG 引入了一个非常务实的工程策略:二次分区(Partitioning),也就是对桶进行“合并与分裂”(Merge & Split)。
这个策略很简单,设定两个阈值:一个最小尺寸 S_min,一个最大尺寸 S_max。
- 如果一个桶里的 Chunks 数量小于
S_min:说明这个桶太小了,内容不够丰富,单独做一个摘要有点浪费。怎么办?就把它和“隔壁邻居”桶合并。“邻居”的选择是基于哈希码的汉明距离,找最接近的。持续合并,直到这个新组合的大小超过S_min。 - 如果一个桶里的 Chunks 数量大于
S_max:说明这个桶太大了,内容可能太泛了。怎么办?就把它分裂成几个更小的子桶,确保每个子桶的大小都不超过S_max。(论文中提到分裂,但更着重于合并的操作,实际的分裂策略可以有多种,比如在桶内再进行一次聚类等)。
经过这一轮合并与分裂的操作,原来的“桶”(Buckets)就被调整成了大小更均匀、粒度更一致的“段”(Segments)。每一个“段”,才是最终用来生成摘要的基本单元。
这个 Merge & Split 的策略,体现了典型的工程智慧:通过简单的规则,在维持语义相关性的前提下,强制保证了基本单元的粒度统一,为后续构建结构均衡、摘要质量稳定的层次图打下了坚实的基础。
2.4 递归构建多层图
现在我们有了一批大小合适的“段”(Segments),接下来就是构建层次图了。这个过程和 RAPTOR 类似,是一个递归的过程:
- 生成第 0 层摘要:对每个“段”里的所有 Chunks,调用一次 LLM,让它生成一个摘要。这个摘要本身也是一个 Chunk,我们称之为“摘要节点”。所有这些摘要节点,就构成了图的第 1 层(如果把原始 Chunks 看作第 0 层的话)。
- 递归向上构建:把第一层生成的所有“摘要节点”,当成新的、更高级别的 Chunks,重复上面的整个过程:
- 将这些摘要节点进行向量化。
- 用同一组保存好的随机超平面,对它们进行 LSH 分桶。
- 对分好的桶进行 Merge & Split,调整成大小合适的“段”。
- 对调整后的“段”进行再次摘要,生成更高一层的摘要节点(第 2 层)。
- 循环往复,直到顶部:这个过程一直重复,直到最顶层的节点数量少于一个阈值(比如无法再形成一个完整的“段”),整个建图过程就结束了。
最终,我们就得到一个层次化的图结构。最底层是原始的、最详细的文本块,越往上,节点的语义粒度越大,内容越概括。
这个结构的好处是,当用户提问时,我们可以同时检索不同层级的节点。
- 如果问题很具体,需要细节,那么底层的叶子节点可能更有用。
- 如果问题很宏大,需要概括性信息,那么高层的摘要节点就正好派上用场。
至此,EraRAG 的静态建图过程就完成了。总结一下关键点:
- 使用基于随机超平面的 LSH 进行分组,保证了语义相似的 Chunks 能聚在一起。
- 核心创新在于“保存超平面”,使得分组过程完全可复现,为增量更新铺平了道路。
- 通过 Merge & Split 策略,保证了摘要单元的粒度均衡,提升了图的结构和摘要质量。
- 通过递归摘要,构建了一个能够支持多粒度查询的层次化图结构。
三、EraRAG 的杀手锏:外科手术式增量更新
前面我们花了大量篇幅讲解 EraRAG 如何建图,所有的铺垫都是为了它真正的“杀手锏”——高效的增量更新。
当一篇新文档到来时,EraRAG 不再需要像其他 Graph-RAG 方法那样“推倒重来”,而是像一个经验丰富的外科医生,只在“病灶”区域动刀,对整个系统的影响降到最低。
我们来看看这个“手术”过程是怎么样的,对应于整体架构图(图 3)的第三部分。
3.1 定位:新来的 Chunk 该去哪?
假设系统里来了一个新的 Chunk,c_new。
- 编码:首先,和初始建图时一样,用同一个 Embedding Model 把它转换成向量
v_new。 - 哈希:接下来是关键一步。拿出我们之前保存好的那一组随机超平面
{h₁, ..., hₖ},对v_new进行哈希计算,得到它的k位二进制哈希码hash(v_new)。
由于超平面是固定的,这个哈希过程是确定性的。v_new 会被精准地、命中注定地分配到它应该去的那个“桶”里。
3.2 局部调整:只在受影响的区域动刀
c_new 被插入到了最底层的某个桶之后,可能会触发这个桶以及周围小范围的一些变化。EraRAG 的更新机制会严格地将影响控制在局部。
- 标记受影响:
c_new加入的那个桶,被标记为“受影响”(affected)。 - 检查尺寸:现在,需要检查这个“受影响”的桶的大小是否还符合我们之前设定的
S_min和S_max规则。- 情况一:桶变大了,但仍在
[S_min, S_max]区间内。 这是最理想的情况。桶的成员变了,但结构没变。我们只需要对这个桶(现在是“段”)重新生成一个摘要就行了。 - 情况二:桶变大了,超过了
S_max。 这个桶需要分裂。它会被分裂成几个更小的桶,这些新分裂出的桶也都会被标记为“受影响”。 - 情况三:一个原本很小的桶,因为
c_new的加入,达到了S_min。 这个桶之前可能和邻居合并了,现在长大了,可以“自立门户”了。这也算是一种结构变化,这个桶和它之前的“家庭成员”都会被标记为“受影响”。
- 情况一:桶变大了,但仍在
- 重新摘要:所有在上面步骤中被标记为“受影响”的段(Segments),都需要重新调用 LLM 生成新的摘要。那些没有被新 Chunk 波及,也没有参与合并或分裂的段,它们的摘要完全不用动。
可以看到,在最底层,只有新 Chunk 及其“邻里”的少数几个段需要重新计算摘要。绝大部分图的节点都安然无恙。
3.3 逐层向上传播更新
底层的摘要节点更新了,就相当于更高一层的“原始 Chunks”发生了变化。这个变化需要像涟漪一样,逐层向上传播。
这个传播过程和我们刚刚在底层做的操作非常相似,也是一个递归的更新过程:
- 定位父节点:一个在第
l层被更新了的摘要节点s_new,它会像一个新 Chunk 一样,通过固定的超平面哈希,被定位到它在第l+1层的归属桶。 - 标记与调整:它加入的那个
l+1层的桶,同样被标记为“受影响”,并根据S_min和S_max进行检查,可能触发合并或分裂。 - 重新摘要:所有在第
l+1层被影响的段,也需要重新生成它们在第l+2层的摘要。 - 循环往复:这个“定位 -> 调整 -> 重新摘要”的过程会一直向上传播,直到某一层不再触发结构性变化(比如,只是一个桶里的成员更新了,但没触发合并分裂),或者传播到图的顶层为止。
这个过程听起来好像挺复杂,但关键在于,每次向上传播,影响的范围通常是收敛的。因为多个底层的变动,可能最终只汇聚到上层的一个节点发生变化。因此,整个更新过程的计算量被严格限制在从新数据点出发,向上延伸的一条或几条“路径”上,而不是整个图。
这就是 EraRAG “外科手术式”更新的精髓:利用可复现的哈希定位,结合局部的合并分裂策略,将更新的范围限制在最小的、必要的子图上,从而极大地降低了维护成本。
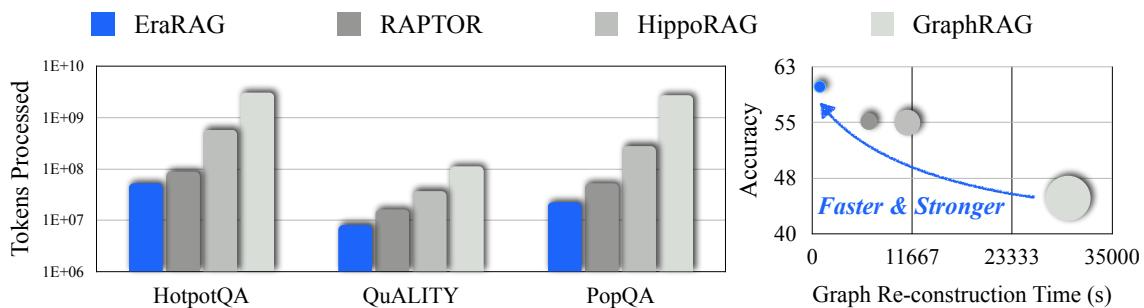
论文中的实验也证明了这一点。下图是在一个小规模增量插入(只插入 1 个文档,2 个 Chunks)场景下的耗时和 Token 消耗。
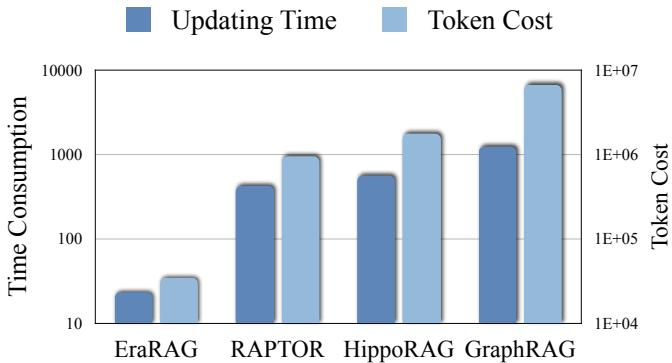
可以看到,EraRAG 的更新时间和 Token 成本相比于 RAPTOR 和 HippoRAG,降低了一个数量级以上;相比于需要全量重建的 GraphRAG,更是降低了两个数量级。这个差距在处理高频、细粒度的更新时,优势极其明显。
四、EraRAG 的检索:平铺后检索
直接把图里所有的节点——无论是底层的原始 Chunk,还是高层的摘要 Chunk——都视为一个扁平的、无差别的集合。
具体分为以下四步:
- 第一步:查询编码 (Query Encoding) 和所有 RAG 系统一样,当用户的提问
q进来后,用跟建图时相同的 Embedding Model,把它转换成一个查询向量e_q。 - 第二步:扁平化检索 (Flat Retrieval) 这是最关键的一步。拿着查询向量
e_q,直接去那个我们之前说的、存储了所有节点向量的 FAISS 数据库里,执行一个 Top-K 相似度搜索。 请注意,这个搜索是全局的,它同时看到了叶子节点(最详细的原文)、第一层摘要节点、第二层摘要节点……并把它们放在同一个“赛场”上进行比较。 - 第三步:内容拼接 (Context Concatenation) FAISS 会返回 K 个最相似的节点 ID。然后,我们根据这些 ID,去元数据存储里把它们对应的文本内容拿出来,简单地拼接成一个长长的上下文(Context)。
- 第四步:生成答案 (Answer Generation) 最后,把用户的原始问题和这个拼接好的、包含多层次信息的上下文,一起打包塞给 LLM,让它生成最终答案。
五、实战评测:又快又准,还很稳
5.1 静态问答能力:不仅快,而且强
首先,我们得确保 EraRAG 为了效率,没有在效果上做太多妥协。论文把它和包括 ZeroShot(LLM 自己想)、Vanilla RAG(朴素 RAG)、以及其他多种 Graph-RAG 方法在内的基线模型进行了比较。评测是在一个静态的、完整的知识库上进行的,不涉及增量更新。
TABLE II: 各模型在多个 QA 基准测试上的表现
| Type | Method | PopQA (Acc/Rec) | QuALITY (Acc) | HotpotQA (Acc/Rec) | MuSiQue (Acc/Rec) | MultihopQA (Acc/Rec) |
|---|---|---|---|---|---|---|
| Graph-based | GraphRAG | 49.98 / 21.28 | 44.9 | 40.84 / 47.39 | 19.32 / 28.81 | 56.98 / 45.53 |
| HippoRAG | 59.29 / 25.88 | 53.31 | 50.46 / 56.12 | 25.15 / 39.71 | 57.49 / 42.17 | |
| RAPTOR | 59.02 / 27.34 | 55.48 | 53.29 / 61.97 | 24.02 / 37.92 | 60.11 / 40.82 | |
| Our proposed | EraRAG | 62.98 / 28.54 | 60.25 | 55.39 / 61.43 | 25.39 / 41.35 | 62.87 / 42.98 |
从上面这张(节选的)表格里,我们可以清晰地看到:
- EraRAG 在绝大多数指标上都取得了最优成绩(SOTA)。
- 特别是在 QuALITY 这个需要深度阅读理解的长文问答数据集上,EraRAG 的准确率达到了 60.25%,比强劲的对手 RAPTOR(55.48%)高出了近 5 个百分点,提升非常显著。
这说明什么?说明 EraRAG 的建图方式不仅是为了方便更新,它本身就是一种非常优秀的图构建策略。其 LSH + Merge & Split 的分区方法,相比 RAPTOR 的重叠聚类,能产生更清晰、冗余更少的语义分块,从而生成了质量更高的摘要,最终提升了下游任务的准确率。
这个结果让人很踏实:EraRAG 不是一个“偏科生”,它在保证了动态更新效率的同时,核心的问答能力也是顶级的。
5.2 动态更新的稳定性:增量≠妥协
静态能力强只是基础,EraRAG 的主战场还是动态场景。那么,通过增量更新构建起来的图,和一次性用全量数据构建的图,在最终的效果上有多大差距呢?
为了回答这个问题,论文设计了一个非常巧妙的实验:
- 基准线(虚线):用 100% 的数据,一次性构建一个完整的 EraRAG 图,然后测试其问答准确率和召回率。这代表了“理想情况”下的性能上限。
- 增量线(实线):先用 50% 的数据构建一个初始图,然后分 10 次,每次把剩下数据的 5% 增量地插入到图中。在每次插入后,都测试一次模型的性能。
我们来看结果图:
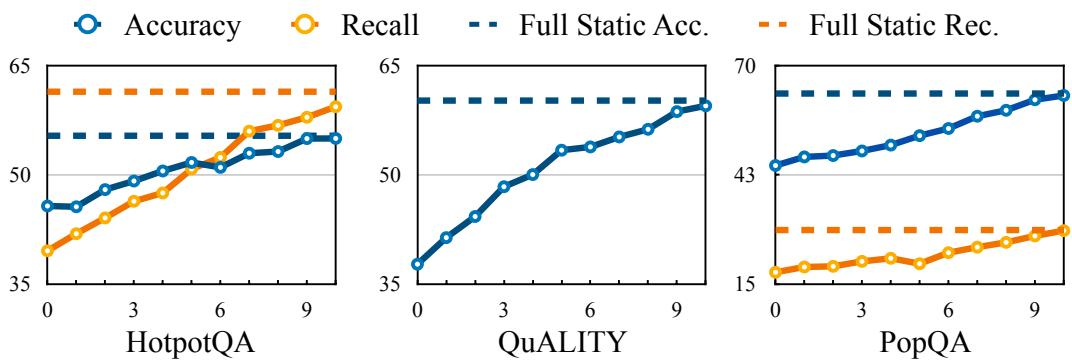
这张图告诉我们两个关键信息:
- 性能稳步提升:随着新数据的不断插入,Accuracy 和 Recall 两条实线都在稳步上升。这说明 EraRAG 的增量更新机制确实能有效地把新知识融入到现有图中,并转化为实实在在的性能提升。
- 最终性能趋于一致:在 10 次增量更新全部完成后,实线的最终点,非常接近代表性能上限的虚线。这意味着,通过“零敲碎打”的增量更新构建起来的图,其最终的问答效果,和用全量数据“一步到位”构建的图,几乎没有差别。
这个结论至关重要。它证明了 EraRAG 的选择性更新机制是鲁棒的,不会因为多次、局部的修改而导致图的结构或语义发生“漂移”或退化。我们用一种高效得多的方式,达到了和“笨办法”几乎一样的效果。
5.3 摘要 vs. 细节:灵活的查询策略
EraRAG 的多层图结构还带来一个额外的好处:可以根据问题的类型,采取不同的检索策略。
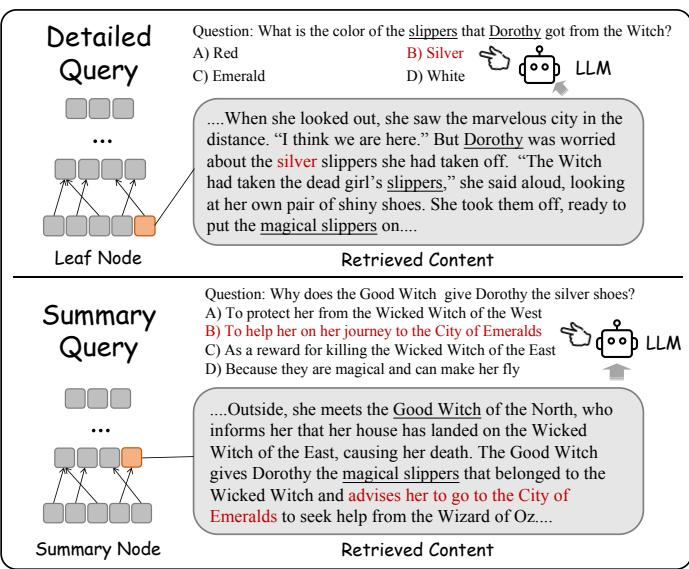
- 细节查询(Detailed search):如果用户问一个非常具体的问题,比如“绿野仙踪里桃乐丝的鞋子是什么颜色?”,答案很可能就藏在某个底层的、原始的文本 Chunk 里。这时候,我们应该优先从叶子节点层进行检索。
- 摘要查询(Summarized search):如果用户问一个概括性的问题,比如“桃乐丝的冒险旅程有哪些主要阶段?”,答案可能需要综合多个段落的信息。这时候,检索那些高层的摘要节点会更有效,因为它们本身就是对大段内容的概括。
论文中提到,EraRAG 支持这种自适应的检索策略,用户可以设置一个比例参数 p,来控制检索回来的 Chunks 中,来自叶子节点和摘要节点的比例。这为不同场景下的应用提供了更大的灵活性。
六、一些总结 & 我的看法
1、“可复现性”是工程设计的灵魂。
EraRAG 整个体系能够成立的基石,就是那个看似简单的“保存超平面”操作。它把一个不确定性的聚类问题,转换成了一个确定性的哈希分配问题。这个转变,使得“局部更新”成为了可能。
2、初始化仍然重要,天下没有免费的午餐。
影响。结果发现,如果一开始只用 10% 的数据建图,后面再慢慢加,最终效果会比一开始用 50%-70% 的数据建图要差一些。这说明,初始图的“骨架”质量,对后续的“生长”有深远影响。一个好的开端,能为系统的长期演进打下坚实的基础。这也提醒我们,在实践中,首次建图时,数据量和代表性还是要尽可能地保证。
七、工程化设想
目前还没有看到项目对此做工程化集成。以下谈谈我的几点设想:
- 关于图构建方案切换 - 如果我们现在做传统 GraphRAG 方案实现,未来能切到 ERA-RAG 么?理论上把 k 个超平面保存下来,使得每次增量数据来的时候,可以进行局部图谱更新。如果我们现在已经做了一套传统的图检索,再上 ERA-RAG 的增量检索方案,就需要对现有的 chunks 构建一遍 ERA-RAG 的分层图
- 关于 ERA-RAG 的图存储 - 想象中,依然做传统 GraphRAG 的本体,三元组抽取,并存储到向量库,只是传统的 GraphRAG 可能额外往向量库存储的是基于 leiden 做的社区信息,或者基于 RAPTOR 做的聚类树,而 ERA-RAG 存储的是其基于超平面切的分层树
- 潜在问题 - 理论上,极限情况下,其实 ERA-RAG 的叶子结点的多米诺骨牌效应的局部更新是有可能导致大面积更新的?比如 Smin 和 Smax 配置的不好,都有合并或者分裂,那么其 Parent 结点也得走一遍更新
Comments