RAG 工程:回味经典 - 解读 RAPTOR 设计
这两天在做技术调研,顺便回味一下这篇入选 ICLR 2024 的经典工作
传统的 RAG,有点“短视”。
它通常把长文档切成一堆互不相干的小碎片,然后根据你的问题,找出最像的几片。这对于回答“XX 是什么?”这种 factual question(事实性问题)还行。可一旦问题需要你通读全文、理解来龙去脉,比如“《三体》这本书到底想表达什么思想?”或者“分析一下这份财报里,公司潜在的经营风险在哪?”,传统 RAG 就拉了胯了。它给你捞上来的可能只是几个包含“三体”或者“风险”的零散段落,跟瞎子摸象没啥区别,根本没法形成整体认知。
为了解决这个“只见树木,不见森林”的毛病,斯坦福大学 Manning 团队的一帮人搞了个新东西,叫 RAPTOR (Recursive Abstractive Processing for Tree-Organized Retrieval)。这名字听着挺唬人,又是递归又是树的。但它的核心思想,简单粗暴又极其有效。
一、传统 RAG 的死胡同:只见树木,不见森林
咱们先设身处地地想一下,为什么传统 RAG 处理长文本这么费劲。
所有问题的根源,都来自那个简单粗暴的步骤:切块(Chunking)。
一个几万甚至几十万字的长文档,比如一本小说、一份法律合同、一篇科研论文,我们没法一口气塞给 LLM(即使现在有了百万token上下文,成本和效率也让人肉疼,更别提模型在超长文本里“迷路”的问题)。所以,标准做法就是把它切成一堆固定长度的小文本块,比如每 100 或 200 个 token 一块。然后用 embedding 模型(比如 SBERT)给每个小块算个向量,存进向量数据库。
来问题了,你就把问题也算个向量,然后去数据库里 select * from chunks order by cosine_similarity(query_vector, chunk_vector) limit 5;。把这 5 个最相似的块(chunks)和你的问题一起打包,丢给 LLM,让它生成答案。这就是所谓的 RAG。
这种方法的致命缺陷是:它彻底破坏了文档的宏观结构和深层逻辑。
一个作者写一本书,是有谋篇布局的。观点A可能在第一章提出,论据B在第三章,结论C在第十章。这三块内容在语义上是强相关的,它们共同构成了一个完整的论证链条。但是,在物理上,它们被远远地分开了。当你问一个关于这个论点的问题时,传统的 RAG 很可能只召回了其中一两个碎片,信息是残缺的。
论文里举了个“灰姑娘”的例子,特别形象。如果你问:“灰姑娘最后是怎么获得幸福结局的?”
一个传统的 RAG 系统可能会从原文里给你找出这么几段:
- “仙女教母挥动魔杖,把南瓜变成了马车……”
- “王子在舞会上对一位神秘的公主一见倾心……”
- “午夜十二点的钟声敲响了,灰姑娘的华服变回了破烂的衣裳……”
这几段虽然都相关,但它们是孤立的事件。LLM 拿着这几块拼图,可能压根就串不起来整个故事线,因为它缺少了关键的转折和结局部分,比如“王子拿着水晶鞋全国寻找意中人”、“水晶鞋正好合脚”、“灰姑娘原谅了她的姐姐们”等等。
所以,问题很明确:我们需要一种新的检索方式,它既能抓取到细枝末节的信息,又能理解和利用文档的宏观主题和逻辑脉络。检索上来的内容,不应该是零散的碎片,而应该是经过整合、有层次的上下文。
RAPTOR 就是为了干这个事儿来的。
二、RAPTOR 的核心玩法:用“递归总结”建一棵知识树
RAPTOR 的思路,听起来可能有点学院派,但你仔细琢磨一下,会发现它非常符合人类理解复杂事物的认知过程。我们读一篇长文,不也是先看各个段落,然后在大脑里把相关的段落归归类,形成几个小的主题,再把这几个小主题整合成一个更大的主题,最后形成对全文的整体印象吗?
RAPTOR 就是在用算法模拟这个“自下而上”的归纳总结过程。它的目标不是存一堆文本碎片,而是要为每一篇长文档,构建一棵专属的、层次化的知识树。
这棵树是怎么建的呢?分三步走。
2.1 第一步:打地基(Layer 0),铺满原始文本块
这一步和传统 RAG 一模一样,没啥新意。
- 切块:把原始文档切成一堆小的、连续的文本块(leaf nodes,叶子节点)。论文里用的标准是 100 个 token 一块。为了保证句子完整性,如果切分点正好在句中,它会把整个句子挪到下一个块里。这个细节很贴心,保证了最底层信息单元的完整。
- 嵌入:用一个 embedding 模型(论文里主要用的是 SBERT 的
multi-qa-mpnet-base-cos-v1模型)把每个文本块转换成一个向量。
搞定。现在我们有了一堆带有向量的文本块。在 RAPTOR 的世界里,这构成了知识树的第 0 层(Layer 0),也就是最底层的叶子。
2.2 第二步:递归盖楼(Layer 1, 2, ...),聚类+总结
这步是 RAPTOR 的独门绝技,也是它和所有其他 RAG 方法拉开差距的地方。它引入了一个循环过程:聚类 -> 总结 -> 再嵌入 -> 再聚类...
让我们跟着这个循环走一遍,看看它是怎么从 Layer 0 盖出 Layer 1 的。
- 聚类(Clustering):把
Layer 0所有文本块的向量(Embeddings)收集起来,然后用一个聚类算法,把它们分成若干个簇(Cluster)。 - 这里的聚类,是整个 RAPTOR 方法的灵魂。它不是按文本在原文中的先后顺序分组,而是根据语义相似度来分组。这意味着,第一章里讨论某个概念的一段话,和第五章里进一步阐述这个概念的另一段话,虽然在原文里隔了十万八千里,但因为它们的向量在空间中很接近,所以有很大概率被分到同一个簇里。
- 这就实现了跨越物理距离的语义连接!
- 具体技术上,论文用的是高斯混合模型(GMM)。你可以把它想象成,假设所有这些文本向量是由好几个不同的“高斯分布源”(也就是主题)生成的。GMM 的任务就是反向推断出这些主题的中心、形状和大小。相比于 K-Means 这种硬聚类(一个点只能属于一个簇),GMM 做的是“软聚类”,一个文本块可以按不同的概率属于多个簇。这也很符合直觉,因为一段话可能同时涉及好几个主题。
- 另外,因为文本向量维度太高(通常是 768 或更高),在高维空间里算距离很容易“翻车”(维度灾难)。所以 RAPTOR 在聚类前,先用 UMAP 这个降维神器把向量维度降下来,同时还能很好地保持数据的局部和全局结构。
- 怎么确定到底该聚成几类呢?论文用了贝叶斯信息准则(BIC),这是一个统计学指标,能在“模型拟合得好”和“模型别太复杂”之间做个权衡,帮你自动找到一个比较合适的聚类数量。
- 总结(Summarization):聚类完成后,我们就得到了一堆“语义小组”,每个小组里都装着若干个来自原文的文本块。接下来,RAPTOR 会对每个小组进行总结。
- 它会把一个簇里所有文本块的原文内容拼接起来,然后调用一个 LLM(论文里用的是
gpt-3.5-turbo),给出一个明确的指令:“请用尽可能多的关键细节,总结以下文本:{拼接后的文本}”。 - LLM 会“阅读”这个簇里的所有内容,然后生成一段高度浓缩的摘要(Summary)。这段摘要,就成了这棵知识树里一个全新的、更高层次的节点。
- 至此,从
Layer 0到Layer 1的构建就完成了。Layer 1的每个节点,都是对Layer 0中某一个语义簇的概括。 - 递归(Recursion):你可能已经猜到了,故事还没完。
- 首先,把
Layer 1生成的所有新摘要,用同一个 embedding 模型,也转换成向量。 - 然后,把
Layer 1的这些向量,再次进行聚类。 - 对聚类后的新簇,再次进行总结,生成
Layer 2的摘要节点。 - 再对
Layer 2的节点进行嵌入、聚类、总结,生成Layer 3...
- 首先,把
这个“聚类-总结”的过程会一直重复下去,直到最后只剩下一个或极少数几个节点,没法再聚类了。这时候,最顶层的那个节点,就相当于对整篇文档的“终极摘要”。
下面这张图,就是 RAPTOR 官方画的树构建过程,一图胜千言。从底部的叶子节点(原始文本块)开始,语义相近的被聚到一起(用虚线框表示),生成了上一层的摘要节点(父节点)。这个过程不断重复,最终形成了一棵层次分明的树。
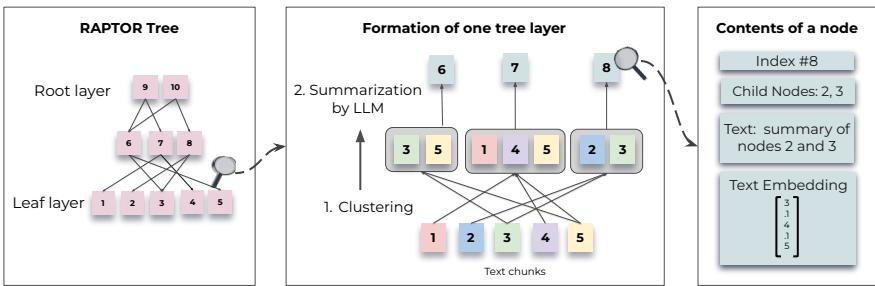
最终,我们就得到了一件神器:一个代表整篇文档的多层次、语义化的索引结构。
- 第 0 层:最原始、最详细的文本细节。
- 中间层:对不同主题、不同粒度的概括和总结。
- 顶层:对全文最高度的抽象和主题概括。
这棵树一旦建好,就可以被持久化存起来,随时等待查询。整个构建过程是离线的,虽然需要调用 LLM 做总结,会产生一些成本,但对于一篇文档,这只是一次性的投入。
三、有了树,怎么检索?两种策略的博弈
好,现在我们手里有了一棵结构精美的知识树。当用户提出一个问题时,我们该怎么利用这棵树来检索信息呢?论文提出了两种很有意思的策略。
3.1 策略一:树遍历(Tree Traversal)
这个方法非常符合直觉,就像在电脑里一层一层地打开文件夹找文件一样。
- 从根开始:计算查询(Query)向量和树的最顶层(比如 Layer 2)所有节点的向量余弦相似度。
- 选择最优路径:选出最相似的
top-k个节点(比如k=1)。 - 向下钻取:现在,我们只看这
top-k个被选中节点的直接子节点。在这些子节点里,再次计算与查询向量的相似度,再选出top-k。 - 重复:一直重复这个过程,一层一层往下走,直到抵达最底层的叶子节点(Layer 0)。
- 收集结果:把整个遍历路径上所有被选中的节点(无论是摘要还是原始文本)都收集起来,拼接成最终提供给 LLM 的上下文。
这个策略的优点是,它模拟了一种“由粗到细”的探索过程。先定位到最相关的大主题,然后在这个大主题的范围内,逐步深入到具体的细节。
3.2 策略二:拍平了再搜(Collapsed Tree)
第二个方法,思路更加狂野,也更加简单。
它说:“去TM的层级结构,在检索的时候,众生平等!”
- 拍平:把树上所有的节点,无论它是
Layer 0的原始文本块,还是Layer 1,Layer 2的摘要,全都取出来,放在一个大池子里。 - 全局搜索:计算查询向量和这个大池子里所有节点向量的相似度。
- 择优录取:按相似度从高到低排序,然后从头开始一个个地拿节点,直到拼接起来的文本总长度达到一个预设的上限(比如 2000 tokens)。
这个方法完全忽略了树的父子关系,把所有粒度的信息都放在了同一个竞技场上,让查询本身来决定需要哪些信息。
下面这张图直观地对比了两种检索方式。左边的“树遍历”是层层递进,每次只在一小部分节点里做选择。右边的“拍平树”则是把所有节点(图中高亮的)看作一个整体,进行一次性的大规模搜索。
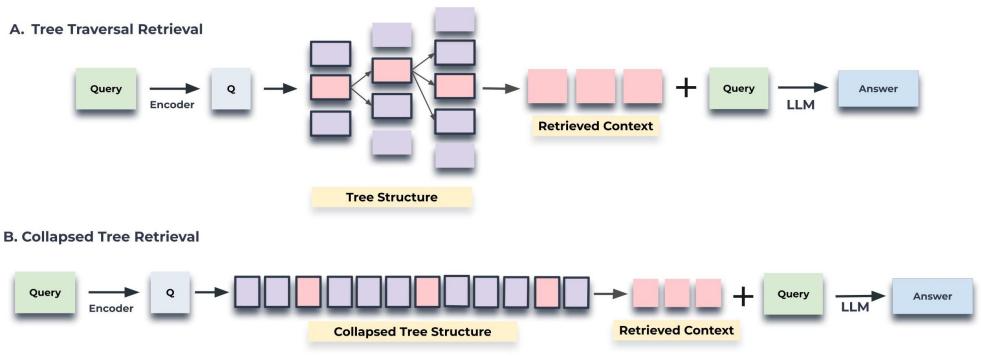
3.3 哪个更好?
你可能觉得“树遍历”听起来更高级、更智能。但论文通过实验(在一个叫 QASPER 的数据集上做了初步测试)发现,“拍平树”(Collapsed Tree)策略的效果 consistently better(持续地更好)。
为什么这个看似“无脑”的方法反而赢了?
核心在于灵活性。
- 当你的问题非常具体,需要原文的某个细节时,“拍平树”可以直接从
Layer 0捞出最相关的那个叶子节点。 - 当你的问题非常宏大,需要对全文主旨的理解时,“拍平树”可以直接捞出
Layer 2或Layer 3的高层摘要节点。 - 当你的问题需要结合宏观背景和具体案例时,“拍平树”可以同时捞出几个高层摘要节点和几个底层的叶子节点,自由组合。
而“树遍历”策略就显得有些僵化。它强制你必须走一条从上到下的路径。如果最优的细节信息,恰好不在顶层最相关主题的分支下,那它就可能被错过。
所以,最终 RAPTOR 选择了“拍平树”作为它的主要查询策略。在 AI 领域,有时候最简单直接的暴力美学,效果反而最好。
四、效果到底怎么样?数据和案例说了算
理论说了这么多,是骡子是马,还得拉出来遛遛。
4.1 控制变量实验:RAPTOR 是个“增强器”
首先,为了证明 RAPTOR 的树结构本身是有效的,而不是因为它用了什么花哨的 embedding 模型,研究者们做了一组非常严谨的对比。他们选了 SBERT, BM25, DPR 这几种常见的检索器,分别测试了“只用原生检索器”和“用原生检索器 + RAPTOR 树结构”两种情况下的性能。
结果(见论文 Table 1, 2, 这里不贴了)非常一致:在 NarrativeQA(书籍电影问答)、QuALITY(长文阅读理解)、QASPER(科研论文问答)这三个数据集上,无论搭配哪种检索器,加上 RAPTOR 的树状结构后,性能都有明显的提升。
比如在 QASPER 数据集上,使用 UnifiedQA-3B 模型作为 reader,SBERT + RAPTOR 比单独用 SBERT 提升了 0.5个 F1 点,DPR + RAPTOR 比单独用 DPR 提升了 0.5个 F1 点。虽然数字看上去不大,但在已经很卷的榜单上,每一点提升都来之不易。
这证明了:RAPTOR 本身不是一个新的检索器,而是一个通用的、可以赋能现有检索器的“增强框架”。 你可以把它看作是你现有 RAG 系统的“外挂升级包”。
4.2 硬碰硬 SOTA 对比:直接登顶
当 RAPTOR 和强大的 LLM(如 GPT-4)结合时,它的威力才真正被释放出来,直接在多个高难度长文本 QA 任务上刷新了 SOTA(State-of-the-art,即当时最好水平)。
- 在 QuALITY 数据集上,
RAPTOR + GPT-4的准确率达到了 82.6%。这是什么概念?之前的 SOTA 记录是 62.3%!RAPTOR 直接把准确率暴力拉高了 20.3 个百分点。 这简直是降维打击。尤其是在该数据集的HARD子集(连人类都觉得难的题目)上,提升更为恐怖。 - 在 QASPER 数据集上,
RAPTOR + GPT-4的 F1 分数达到了 55.7%,也超过了之前的 SOTA 模型 CoLT5 XL 的 53.9%。 - 在 NarrativeQA 数据集上,
RAPTOR + UnifiedQA在 METEOR 指标上同样创造了新的 SOTA 记录。
这些冰冷的数据证明了 RAPTOR 在处理需要深度、整体理解的长文本问答任务上,确实有两把刷子。
4.3 案例分析:RAPTOR 为什么这么牛?
为了更直观地感受 RAPTOR 的优势,我们再回到“灰姑娘”的例子。论文里用了一张图,生动地展示了 RAPTOR 和传统 DPR(一种经典的稠密检索方法)在回答两个不同问题时,检索到的内容有何天壤之别。
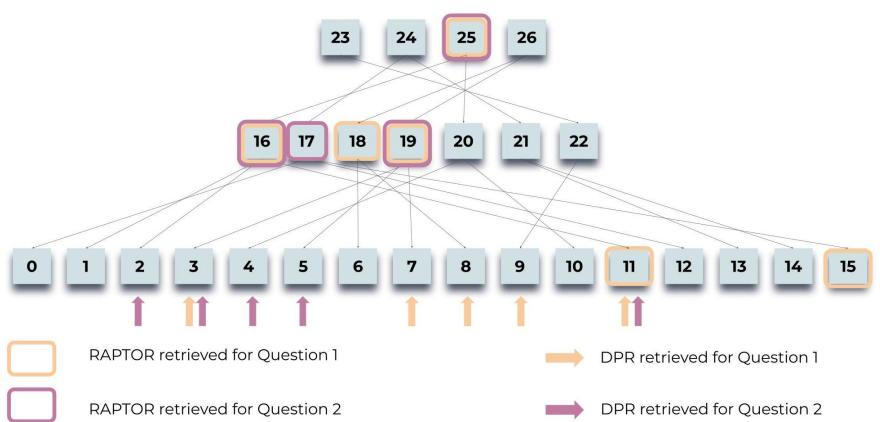
上图中,高亮的节点是 RAPTOR 选中的,而箭头指向的叶子节点是 DPR 选中的。
- 问题1(宏观主题):“这个故事的核心主题是什么?”
- DPR 找来的:是一些非常具体的细节,比如“两只老鼠变成了仆人”、“仙女把灰姑娘的破衣服变成了华服”。这些只是故事的一部分,无法概括主题。
- RAPTOR 找来的:主要是中间层的摘要节点,内容涵盖了“仙女帮助灰姑娘参加舞会”、“灰姑娘给王子留下深刻印象”、“王子通过水晶鞋找到灰姑娘”、“她原谅了姐姐们”。 这些摘要节点串联起了整个故事的核心脉络,使得 LLM 能够轻松总结出“坚韧、善良最终战胜逆境”的主题。
- 问题2(多跳推理):“灰姑娘是如何找到幸福结局的?”
- DPR 找来的:主要还是关于舞会前变身的细节,以及钟声敲响后魔法消失的片段。对于“如何找到幸福”,信息量严重不足。
- RAPTOR 找来的:不仅包含了舞会的部分,还重点检索到了一个关键的摘要节点:“王子寻找丢失水晶鞋的主人,并发现它属于灰姑娘。她原谅了她的姐姐们,王子很高兴找到了她。” 这个摘要节点本身就是对多个原文片段的“多跳”总结,直接提供了答案的核心部分。
通过这个例子,我们可以看到 RAPTOR 的优势所在:它能够根据问题的抽象层次,动态地选择最合适粒度的信息。 宏观问题匹配宏观摘要,细节问题匹配底层文本。这种自适应的能力,是传统“一刀切”的 RAG 方法望尘莫及的。
五、我的一些看法 & 总结
1、语义聚类 > 邻近关系
很多号称能处理长文本的 RAG 框架,比如前几年的 LlamaIndex,也搞过类似的树状摘要,但它们大多是基于“邻近原则”,比如把相邻的 5 个块总结成一个父节点。RAPTOR 的高明之处在于它用了语义聚类。它打破了物理位置的束缚,把真正“聊的是一回事”的内容聚合在一起。这就让摘要的质量和相关性发生了质变。
2、“拍平树”检索,简单但值钱。
它完美解耦了“索引构建”和“检索查询”两个阶段。构建时,我们不遗余力地打造精细的层次结构;检索时,又返璞归真,给予查询最大的自由度。这不仅效果好,对我们工程实现也极其友好。我们不需要搞什么复杂的图数据库或图遍历算法,只需要把树上所有节点(带上它们的向量)一股脑丢进我们熟悉的向量数据库(比如 Milvus, Pinecone, FAISS)里就行了,用最标准、最高效的 ANN(近似最近邻)搜索。
3、RAPTOR 是一个“框架”,而不是一个“模型”。
RAPTOR 提供的是一套思想和工作流。你可以很方便地替换其中的任何一个组件。Embedding Model 或者 Chat Model。
六、工程化实现
大名鼎鼎的 RAGFlow 已对此方法做了工程化集成:https://ragflow.io/docs/enable_raptor
这里简单聊聊其实现:
构建
# rag/raptor.py
class RecursiveAbstractiveProcessing4TreeOrganizedRetrieval:
# ... 初始化方法略 ...
# 核心递归逻辑
async def __call__(self, chunks, random_state, callback=None, task_id: str = ""):
# chunks: 包含 [(text, vector), ...] 的列表
# 递归循环:只要还有层级可以构建(end - start > 1 表示还有未处理的节点)
while end - start > 1:
# ... 省略任务取消检查 ...
embeddings = [embd for _, embd in chunks[start:end]]
# --- 步骤 A: 降维 (UMAP) ---
# 将高维向量降维,以便 GMM 聚类
reduced_embeddings = umap.UMAP(
n_neighbors=max(2, n_neighbors),
n_components=min(12, len(embeddings) - 2),
metric="cosine",
).fit_transform(embeddings)
# --- 步骤 B: 聚类 (GMM + BIC) ---
# _get_optimal_clusters 内部使用 GaussianMixture 计算最佳簇数量
n_clusters = self._get_optimal_clusters(reduced_embeddings, random_state, task_id=task_id)
# 计算每个点属于哪个簇
gm = GaussianMixture(n_components=n_clusters, random_state=random_state)
gm.fit(reduced_embeddings)
probs = gm.predict_proba(reduced_embeddings)
# 筛选出属于该簇概率大于阈值的节点(Soft Clustering)
lbls = [np.where(prob > self._threshold)[0] for prob in probs]
# --- 步骤 C: 并发生成摘要 ---
async with trio.open_nursery() as nursery:
for c in range(n_clusters):
# 找到属于当前簇的所有 Chunk 的索引
ck_idx = [i + start for i in range(len(lbls)) if lbls[i] == c]
# 启动异步任务去调用 LLM 写摘要
nursery.start_soon(summarize, ck_idx)
# 更新指针,准备处理下一层(即刚刚生成的摘要层)
start = end
end = len(chunks)
return chunks
# 内部摘要函数
async def summarize(ck_idx: list[int]):
# 拼接当前簇内的所有文本
texts = [chunks[i][0] for i in ck_idx]
cluster_content = "\n".join([truncate(t, max(1, len_per_chunk)) for t in texts])
# 调用 LLM 生成摘要
cnt = await self._chat(..., self._prompt.format(cluster_content=cluster_content), ...)
# 计算新摘要的向量(用于下一轮聚类或最终检索)
embds = await self._embedding_encode(cnt)
# 将结果追加到 chunks 列表中
chunks.append((cnt, embds))
存储
存到 ES
# rag/svr/task_executor.py
async def run_raptor_for_kb(row, kb_parser_config, chat_mdl, embd_mdl, vector_size, callback=None, doc_ids=[]):
# 这是一个虚拟的 Doc ID,用于标记这些 Chunk 是 RAPTOR 生成的
fake_doc_id = GRAPH_RAPTOR_FAKE_DOC_ID
# ... 调用 raptor 实例生成 chunks ...
# chunks = await raptor(...)
res = []
# 遍历生成的摘要 (跳过原始 chunks)
for content, vctr in chunks[original_length:]:
d = copy.deepcopy(doc)
# 生成唯一 ID
d["id"] = xxhash.xxh64((content + str(fake_doc_id)).encode("utf-8")).hexdigest()
# 存储向量
d[vctr_nm] = vctr.tolist()
# 存储摘要文本
d["content_with_weight"] = content
# 分词,用于全文检索
d["content_ltks"] = rag_tokenizer.tokenize(content)
d["content_sm_ltks"] = rag_tokenizer.fine_grained_tokenize(d["content_ltks"])
res.append(d)
return res, tk_count
检索
- 因为 RAPTOR 摘要块和普通文档块都在同一个索引(Index)里。
- 当用户提问时,生成的 Query 向量会同时与底层细节块和高层摘要块计算相似度。
- 如果问题是宏观的(如“主要讲了什么”),RAPTOR 生成的高层摘要向量会更接近 Query,从而被召回。
- 如果问题是微观的(如“某参数是多少”),底层原始切片会被召回。
# rag/nlp/search.py -> search()
# 这里的 sres 会同时包含普通文档块和 RAPTOR 摘要块
# 因为它们在同一个 Index 中,且都有 content_with_weight 和 vector 字段
res = self.dataStore.search(src, highlightFields, filters, matchExprs, ...)
Comments